翻译自:http://doc.akka.io/docs/akka/2.3.8/general/supervision.html
督导与监控
本章大概描述督导背后的概念,提供的原语和语义。如何转换成实际代码的细节请参考相关的 Scala 和 Java API。
督导意味着什么
如 Actor 系统 里描述的,督导描述了 actors 之间的依赖关系:督导者委托任务给下属,因此必须为它们的失败负责。当一个下属检测到一个失败(例如抛出异常),它挂起自己和它的所有下属,它的督导者发送一个提示失败的消息。取决于被督导的工作的性质和失败的性质,督导者有下面四个选择:
- 让下属继续执行,保持当前的内部状态;
- 重启下属,清理它的当前内部状态;
- 永久停止下属;
- 向上传递失败,使自己失败。
总是把一个 actor 当作督导层级的一部分是很重要的,这解释了四种选择的存在(一个督导者也是另一个更高级的督导者的下属),且前三者暗示着:让一个 actor 继续执行将执行它的所有下属,重启一个 actor 将重启它的所有下属(但有更多细节见下面),相似地,终止一个 actor 将终止它的所有下属。要注意的是,Actor 类的 preRestart 钩子的默认行为是在重启前终止它的所有下属,但这个钩子可以被覆写;在这个钩子被执行后,递归重启被应用到所有的孩子上。
每个督导者配置了一个函数来翻译所有可能的失败原因(如异常)到上面给出的四种选择之一;注意,这个函数不接受失败的 actor 本身作为输入。很容易提出一种示例结构让这个看起来不够灵活,例如,希望为不同的下属应用不同的策略。此刻,明白督导是形成递归的失败处理结构是很重要的。如果你尝试在某一层做太多,将难以理解,因此,对这种情况推荐的方式是添加一个督导层级。
Akka 实现了一个叫做”父督导“的形式。Actors 只能由其他 actors 创建(顶级 actor 由类库提供),每个被创建的 actor 由它的父亲督导。这种限制使得 actor 的树形层次拥有明确的形式,并提倡合理的设计方法。 必须强调的是这也同时保证了actor们不会成为孤儿或者拥有在系统外界的监管者(被外界意外捕获)。还有,这样就产生了一种对 actor 应用(或其子树)自然又干净的关闭过程。
警告:督导有关的父子通信通过特殊的系统消息发生,这些系统消息有自己的邮箱,与用户消息隔离。这暗示着督导有关的事件的顺序相对于普通消息不是确定的。通常,用户不能影响普通消息和失败通知的顺序。更多细节见 讨论:消息顺序 章节。
顶级督导者
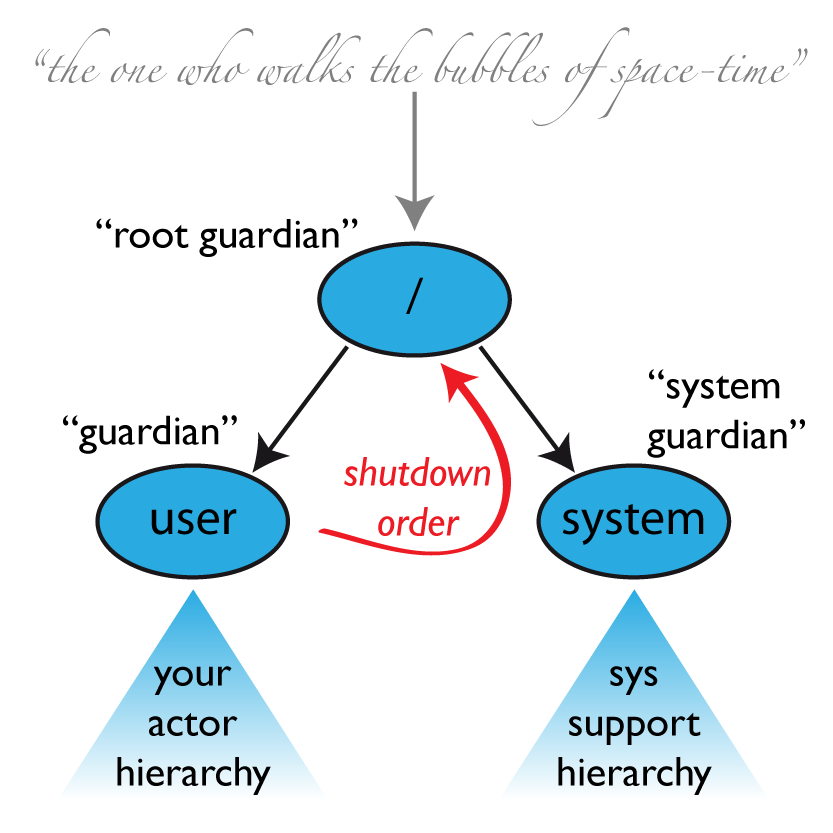
一个 actor 系统在它启动时创建至少三个 actor,如上图所示。关于 actor 路径的更多信息见 Actor 路径的顶级域。
/user:守护者 Actor
这个 actor 可能是与所有用户创建的 actor 交互最多的,这个守护者命名为 "/user"。用 system.actorOf() 创建的 actors 都是这个 actor 的孩子。这意味着当这个守护者终止时,这个系统里的所有普通 actor 也将被关闭。这也意味着,这个守护者的督导策略决定了顶级普通 actors 将被如何督导。从 Akka 2.1 开始,这可以通过设置 akka.actor.guardian-supervisor-strategy 来配置(督导策略),它接受一个 SupervisorStrategyConfigure 的完全类路径名。当这个守护者向上抛出失败时,根守护者负责终止这个守护者,这将导致整个 actor 系统关闭。
/system:系统守护者
引入这个特殊的守护者是为了达到有序地关闭,当所有普通 actor 终止时日志记录剩余存活的,虽然日志记录本身也是用 actors 实现的。这是通过让系统守护者监控用户守护者并在接收到 Terminated 消息时初始化它自己的关闭流程来实现的。顶级的系统 actors 用在遇到除 ActorInitializationException 和 ActorKilledException 外的所有 Exception 时无限制地重启的策略来督导的,这将终止所有的孩子。所有其他 throwables 将向上抛出,将关闭整个 actor 系统。
/:根守护者
这个根守护者是所有被称为“顶级” actor 的父亲,用 SupervisorStrategy.stoppingStrategy 督导在 Actor 路径的顶级域 里提到的所有特殊 actors,它的目的是在遇到任何类型的 Exception 时终止孩子。所有的 throwables 将向上抛出—-但给谁?因为每个实际的 actor 有个督导者,根守护者的督导者不可能是个实际的 actor。这意味着它是“泡沫之外”的,它也被称为“泡沫行者”(译注:有人把宇宙比喻为一个泡沫)。这是一个合成的 ActorRef,它的作用是一旦出现问题的征兆就停止它的孩子,一旦根守护者完全终止(所有孩子递归地停止了)就尽快设置 actor 系统的 isTerminated 状态为 true。
重启意味着什么
当一个 actor 处理某个特定的消息失败时,导致失败的原因分为三类:
- 对接收到的特定消息出现系统(如编程)错误
- 处理消息使用的外部资源(临时)失败
- actor 内部状态被破坏
除非失败是明确地识别了,否则第三种原因不能被排除,这引向内部状态需要被清除的结论。如果督导者决定它的其他孩子或它自己没有被破坏影响(比如因为清楚程序的 error kernal pattern),那么最好重启这个孩子。这引出了通过创建一个新的底层 Actor 实例来替换孩子的 ActorRef 内部那个失败了的实例,能这样做是用特殊的引用来封装 actors 的一个理由。新的 actor 继续处理它的邮箱,意味着重启在 actor 自身外部是不可见的,值得注意的是导致失败的那个消息是不会再次处理了。
重启过程中事件的精确顺序如下:
- 暂停 actor(这意味着它将不再处理普通消息直到被恢复),递归地暂停所有孩子
- 调用旧实例的
preRestart钩子(默认是发送终止请求给所有孩子并调用postStop) - 等待所有在
preRestart过程中处于被要求终止(用context.stop())的孩子真正地终止,这像所有的 actor 操作一样不是阻塞的,最后一个被杀死孩子的终止通知影响继续进入下一步 - 再次调用最初提供的工厂创建一个新的 actor 实例
- 调用新实例的
postRestart(默认也会调用preStart)钩子 - 发送重启要求给所有在步骤 3 杀死的孩子,重启孩子将遵循同样的递归步骤,从步骤 2 开始
- 恢复执行 actor
生命周期监控意味着什么
注意:生命周期监控在 Akka 里通常意味着
DeathWatch。
相比于上面描述的父与子之间的特殊关系,每个 actor 可以监控任意一个 actor。因为受督导的影响,actors 摆脱了创建完全存活和重启对外部是不可见的,唯一可监控的状态改变是从存活到死亡的转变。监控因此用于把一个 actor 绑定到另一个上,这样它可以对另一个 actor 的终止做出反应,相对的是,督导是对失败做出反应。
生命周期监控通过监控者 actor 接收一个 Terminated 消息来实现,如果没有其他处理,默认的行为是抛出一个特殊的 DeathPactException 。为了开始监听 Terminated 消息,调用 ActorContext.watch(targetActorRef) 。为了停止监听,调用 ActorContext.unwatch(targetActorRef)。一个重要的性质是,消息传递与监听请求和目标终止发生之间的顺序无关,例如,即使注册(监听)时目标已经死亡,你仍然可以收到消息。
监控在督导者不能简单地重启它的孩子、必须终止时特别有用,例如,在 actor 初始化时出现错误。在那种情况下,应该监控那些孩子并重新创建它们或调度(父 actor)它自己去稍后重试。
另一个常见用例是一个 actor 需要失败,如果缺少某个外部资源,可能是它自己的孩子。如果有个第三方通过 system.stop(child) 或发送一个 PoisonPill 消息来终止了一个孩子,督导者可能会受到影响。
One-For-One 策略 VS. All-For-One 策略
Akka 提供了两种督导策略: OneForOneStrategy 和 AllForOneStrategy。两者都可以配置异常类型到督导指令(见 前面)的映射,且限制了一个孩子在终止前可以允许多久失败一次。两者之间的区别是,前者只在失败了的孩子上应用获得的指令,后者还会应用在所有(失败actor的)兄弟上。通常,你应该使用 OneForOneStrategy ,如果没有显式指定,这也默认的。
AllForOneStrategy 可用在全体孩子之间有紧密依赖的场景,一个孩子失败了会影响其他的,例如,它们是密不可分的。因为重启不会清空邮箱,出现失败时最好是终止孩子,从督导者(通过监控孩子的生命周期)显式地重新创建它们;否则你需要确保任何一个 actor 在重启前接收到消息并存入邮箱,后面继续处理这个消息是没有问题的。
通常,在 all-for-one 策略里,停止一个孩子(例如不是为了响应失败)是不会自动终止其他孩子的;通过监控它们的生命周期是很容易做到的:如果督导者不处理 Terminated 消息,将抛出 DeathPactException ,这(取决于它的督导者)会重启它,默认的 preRestart 行为会终止所有的孩子。当然,这也可以显示地处理。
请注意,从一个 all-for-one 的督导者创建一次性的 actor 使失败升级,临时的 actor 将影响所有永久的 actors。如果这不是期望的,设置一个中间的督导者;这可以通过声明一个 worker 数量为 1 的 router 来轻易做到,见 路由-scala 或 路由-java。
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。
