TCP通过确认从另一端收到数据来提供可靠的运输层,由于数据和确认都有可能丢失,TCP通过在发送时设置一个定时器来解决这种问题,当定时器溢出时还没有收到确认,它就重传该数据。对于任何实现而言,关键在于超时和重传的策略。
对于每个连接,TCP管理4个不同的定时器:
- 重传定时器 使用于当希望收到另一端的确认。
- 坚持(persist)定时器 使窗口大小信息保持不断流动,即使另一端关闭了其接收窗口。
- 保活(keepalive)定时器 可检测到一个空闲连接的另一端何时崩溃或重启。
- 2MSL定时器 测量一个连接处于 TIME_WAIT 状态的时间。
在进行超时重传时,两次重传的时间间隔是一个倍乘关系(每次增加1倍),称为“指数退避(exponential backoff)”。
往返时间测量
TCP超时与重传中最重要的部分就是对一个给定连接的往返时间(RTT)的测量,这是一个变化的值。TCP应该跟踪这个时间并相应地改变其超时时间。
拥塞避免算法
拥塞避免算法是一种处理分组丢失的方法。
有两种分组丢失的指示:发生超时和接收到重复的确认。(如果使用超时作为拥塞指示,则需要使用一个好的RTT算法)
拥塞避免算法和慢启动算法是两个目的不同、独立的算法。当拥塞发生时,我们希望降低分组进入网络的传输速率,可以调用慢启动来做到这点。
拥塞避免算法和慢启动算法需要对每个连接维持两个变量:一个拥塞窗口cwnd和一个慢启动门限ssthresh。工作过程如下:
- 对一个给定的连接,初始化cwnd为1个报文段,ssthresh为65535个字节。
- TCP输出例程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送方感受到的网络拥塞的估计,后者与接收方在该连接上的可用缓存大小有关。
- 当拥塞发生时(超时或收到重复确认),ssthresh被设置为当前窗口大小的一半(cwnd和接收方通告窗口大小的最小值,但最少为2个报文段)。此外,如果是超时引起的拥塞,则cwnd被设置为1个报文段(也就是慢启动)。
- 当新的数据被对方确认时,就增加cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免。如果cwnd小于或等于ssthresh,则正在进行慢启动,否正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生时所处位置的半时候(步骤3 拥塞发生时的窗口大小会被记录)才停止,然后转为执行拥塞避免。
慢启动算法初始设置cwnd为1个报文段,此后每收到一个确认就加1个,这会使窗口按指数方式增长。
拥塞避免算法要求每次收到一个确认时将cwnd增加 1/cwnd。这是一种加性增长(additive increase)。
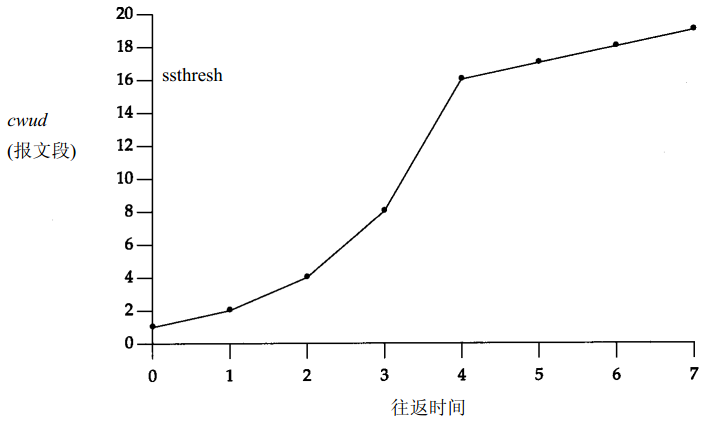
在上图中,假定当cwnd为32个报文段时就会发生拥塞,于是设置ssthresh为16个报文段,而cwnd为1个报文段。在时刻0发送了一个报文段,并假定在时刻1收到它的ACK,此时cwnd增加为2.接着发送了2个报文段,并假定在时刻2接收到它们的ACK,于是cwnd增加为4(对每个ACK增加1次)。这种指数增加算法一直进行到在时刻3和4之间收到8个ACK后cwnd等于ssthresh时才停止,从该时刻起,cwnd以线性方式增加,在每个往返时间内最多增加1个报文段。
重新分组
当TCP超时并重传时,它不一定要重传同样的报文段,TCP允许进行重新分组而发送一个较大的报文段,这将有助于提供性能。因为TCP是使用字节序号而不是报文段序号来进行识别它所要发送的数据和进行确认。
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。
