本站文章索引
特色
回复
9月5、6号两天,有个古老的应用连续出现频繁的 FullGC,最终OOM。
这个古老应用的框架是十多年前基于 Spring 魔改的,在部署上分为 web、app 两层,web通过 EJB 进行调用app里的服务访问数据库。
这两层访问 Spring 容器里的 Bean 一般都是通过类似下面的写法来获取:
SomeService service = CustAppContextHolder.getContext(contextName).getBean(beanName);
service.doSomething();
// CustAppContextHolder.getContext 的实现大致如下:
public class CustAppContextHolder {
private static Map<String, WeakReference
public static ApplicationContext getContext(String contextName) {
WeakReference<ApplicationContext> weakReference = caches.get(contextName);
ApplicationContext context;
if (weakReference != null && (context = weakReference.get()) != null) {
return context;
} else {
synchronized (CustAppContextHolder.class) {
context = initContext(contextName);
caches.put(contextName, new WeakReference<>(context));
}
}
return context;
}
private static ApplicationContext initContext(String contextName) {
System.out.println("init context:" + contextName);
return null;
}
}
工作中经常接触一些 Oracle 的存储过程,里面各种复杂的业务逻辑,在调用存储过程之前、之后的 Java 代码里还有各种业务逻辑操作。
存储过程里还可能有显式的 commit/rollback 等事务控制语句,容易让人对系统的事务管理产生困惑。
对于事务管理,可以从 Oracle 数据库和 JDBC 应用端两个角度来说。
对于 Oracle 数据库,只有碰到 commit 语句时才会提交事务,然后开启新事务;碰到 rollback,回滚当前事务的操作,再开启新事务。
应用端角度通过 JDBC 与数据库进行交互,JDBC 有两种事务管理模式:自动提交(默认)、手动管理。
对于自动提交模式,JDBC 向数据库发出一个 SQL 命令后,如果 SQL 执行成功,则发出 commit 提交事务,否则发出 rollback 回滚事务。
回到标题,一次存储过程调用是一个事务吗?如果存储过程里没有显式的 commit/rollback 语句,且 JDBC 是自动提交的,那么一次存储过程调用就是一个事务。
生产有个功能是上传一个 excel 来进行批量数据操作,excel 里面有三列数据,构建出来的查询大概如下:
select * from t_test t where (t.col1, t.col2, t.col3) in (
(:1, :2, :3),
(:4, :5, :6)
)
IN 子句的长度取决于上传的 excel 里的行数,每一行对应一个 元组。
由于没有限制 excel 里最大行数,导致构建出来的 SQL 有1万多个绑定变量,然后这个 SQL 一直处于解析中,阻塞了这个表上的其他操作(当时主要是插入操作)。(DBA 联系厂商分析给出的结论)
之前一直以为 IN 的列表不能超过 1000,那么生产为什么没有报错,当时拿了那个引发问题的 excel 文件在测试环境复现,是可以正常执行完成的。
DBA 的解释是 11g 里不会报错,19c 开始会报错。DBA 另外提到 IN 列表过长的执行效率是不高的,IN 列表每多一行,执行计划 UNION ALL 下也多一行:

今天重新提起这个,有同事写了个 SQL 在本地验证是报错的:
select * from t_test t where t.col1 in (1, 2, 3, ..., 1001);
为啥当时测试环境复现通过,这个为啥报错?必须搞清楚了。
最近碰到一个问题:项目的数据库连接池使用的是 HkiariCP,对每个 SQL 语句的执行超时时间设置为 30秒,结果有个 SQL 超时了,抛出异常 SQLTimeoutException,应用层回滚事务时抛出了连接已关闭的异常。但事实上事务却提交了。
写了个简单的代码来模拟生产场景:
在 Spring 的声明式事务内,有一个 insert 操作,然后是一个 update 操作,在数据库客户端执行 select for update 把要更新的行锁住,这样 update 操作就会超时。
多次调试发现 HikariCP 在碰到 SQL 异常时有个检查机制,满足特定条件的异常会直接关闭底层数据库连接,Spring 拿到的是连接的代理,由于连接已关闭,自然没法回滚事务,会碰到连接已关闭异常。
最近碰到一个现象或者说问题,同一个 JSON 格式的字符串,Spring 默认的 Jackson 类库解析报错,fastjson 却没报错、正常解析了。
场景大概是这样的,有个类有个日期属性,格式指定为 “yyyy-MM-dd”。
@Data
static class Person {
@JsonFormat(pattern = "yyyy-MM-dd", timezone = "GMT+8") // Jackson
@JSONField(format = "yyyy-MM-dd") // fastjson
Date birthDay;
@JsonFormat(pattern = "yyyy-MM-dd", timezone = "GMT+8")
@JSONField(format = "yyyy-MM-dd")
Date today;
String name;
}
测试代码如下
public void testFastJson() throws JsonProcessingException {
String json = "{\"birthDay\":\"2022710\", \"name\": \"coderbee\", \"today\":\"2022-07-10\"}";
Person person = JSONObject.parseObject(json, Person.class);
System.out.println(person); // 输出解析到对象
System.out.println(JSONObject.toJSONString(person)); // 把对象转换为 JSON 字符串,再输出。
ObjectMapper mapper = new ObjectMapper();
Person jacksonPerson = mapper.readValue(json, Person.class);
System.out.println(jacksonPerson);
}
在之前的文章《踩坑 Druid 连接池》说踩了坑,后面经人提醒,发现根因是一个等待获取连接的 Job 线程被终止了,通过直接调用线程的 stop 方法终止的,这种方式破坏了 ReentrantLock 锁的模型。
下面这个方法是在持有锁的情况下执行的,执行到 1491 行时,job 线程会把自己加入条件对象的等待队列、然后释放锁,等待其他线程来唤醒;
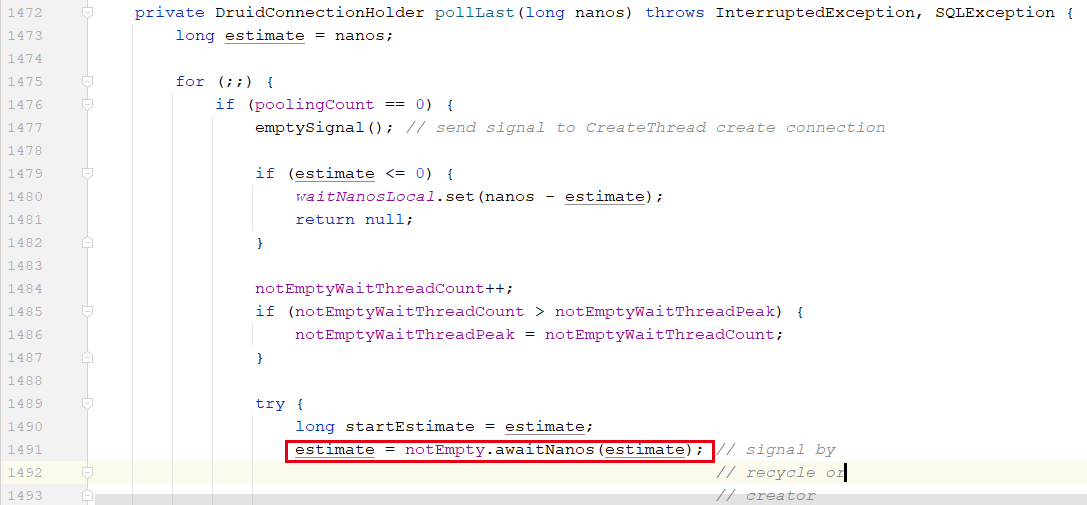
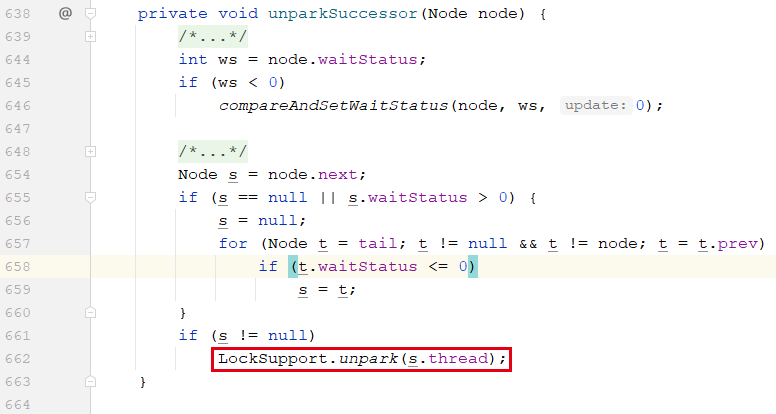
其他线程调用 notEmpty.signal() 方法时,会把 job 线程从条件对象的等待队列转移到 AQS 的获取队列上,让 job 线程重新获取锁、继续执行。
当上一个持有锁的线程释放锁后,它会唤醒下一个,即执行 662 行。
最近看到逻辑类似下面的代码:
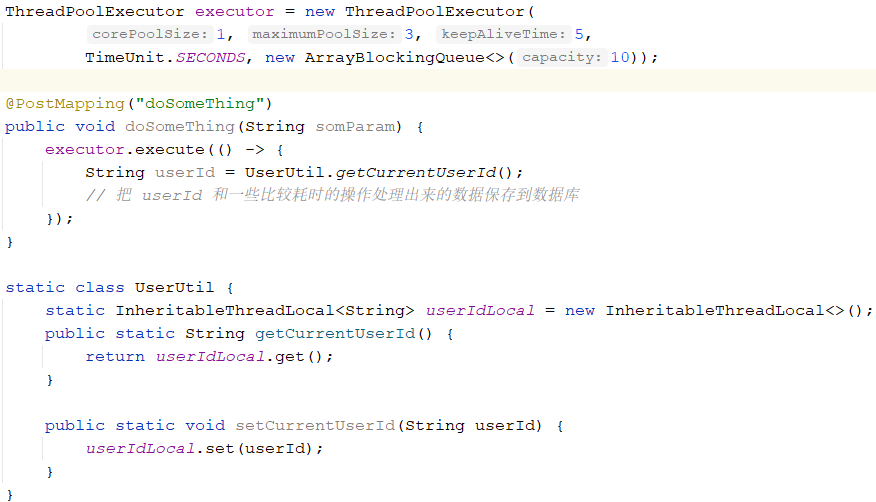
乍一看,我觉得那段异步执行的代码是没法正确把 userId 保存进数据库的,查了数据发现保存的没有问题。呃,有点意思了,为啥没有问题呢。。。
看了 UserUtil 的源码、线程池 executor 实例的初始参数、以及这个接口的请求频率后,想明白了为什么没有踩坑。
但坑是在的,一个坑没有踩中不代表不存在,可以想想请求频率什么样的时候,这个逻辑就会踩坑呢。
问题是出现在 24 号的时候,当时有台 weblogic 实例出现阻塞,运维 dump 线程栈后重启了,有个同事进行分析。
该同事分析线程栈后认为问题出在一个被外部系统调用的接口,这个接口收到请求后会从数据库查询数据,然后把数据处理后发提交到线程池,再由线程池异步发送到 MQ 服务器,调用方监听 MQ 进行数据处理,接口代码大致如下:
这周有个应用的一个实例出现了没有响应,庆幸运维那边在重启前做了线程和内存的 dump 。
线程 dump 文件打开一看,竟然4万多行。。后来发现同事用一个可视化工具来分析线程栈,我也把这个工具加入工具箱:IBM Thread and Monitor Dump Analyzer for Java
下图是这个工具的方法栈分析视图:
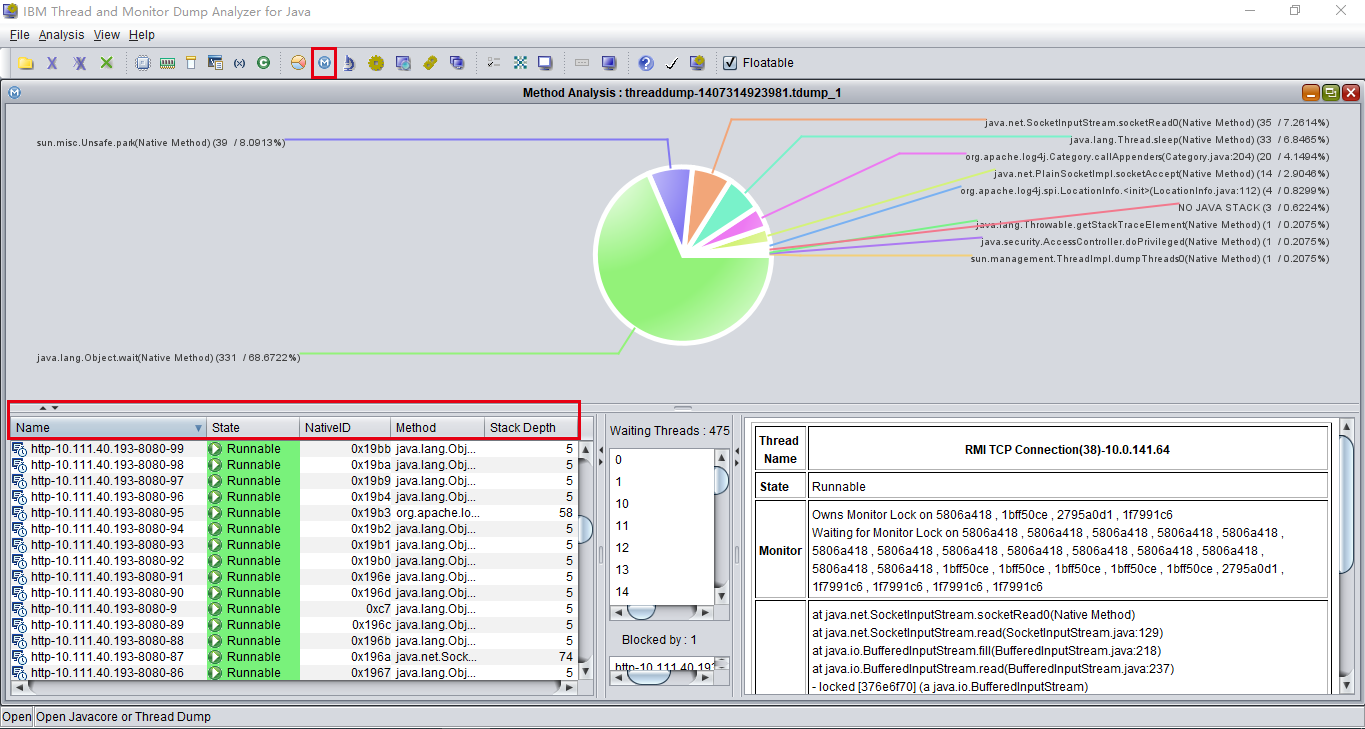
可以按线程名词、状态、方法栈的深度来进行排序。
下面说说这次踩的坑。
一个事务管理器只需要三个基本的能力:获取一个事务、提交事务、回滚事务。
public interface PlatformTransactionManager extends TransactionManager {
// 获取一个事务
TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException;
// 提交事务
void commit(TransactionStatus status) throws TransactionException;
// 回滚事务
void rollback(TransactionStatus status) throws TransactionException;
}
DataSourceTransactionManagerAutoConfiguration 配置类导入了数据库事务管理器 DataSourceTransactionManager。
事务同步回调钩子让我们有机会在事务的各个阶段加入一些协调的动作。
public interface TransactionSynchronization extends Flushable {
/** Completion status in case of proper commit. */
int STATUS_COMMITTED = 0;
/** Completion status in case of proper rollback. */
int STATUS_ROLLED_BACK = 1;
/** Completion status in case of heuristic mixed completion or system errors. */
int STATUS_UNKNOWN = 2;
default void suspend() {}
default void resume() {}
default void flush() {}
default void beforeCommit(boolean readOnly) {}
default void beforeCompletion() {}
default void afterCommit() {}
default void afterCompletion(int status) {}
}