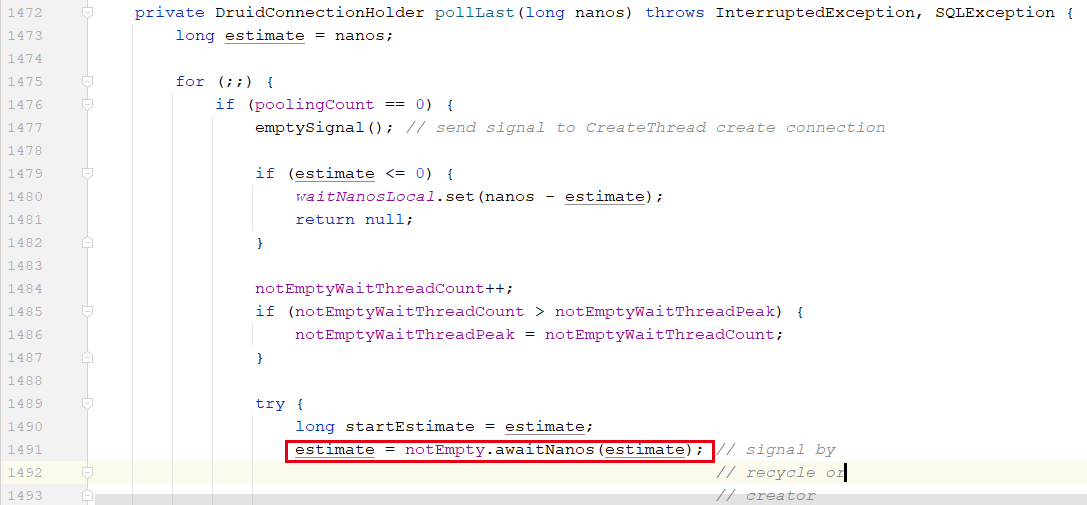
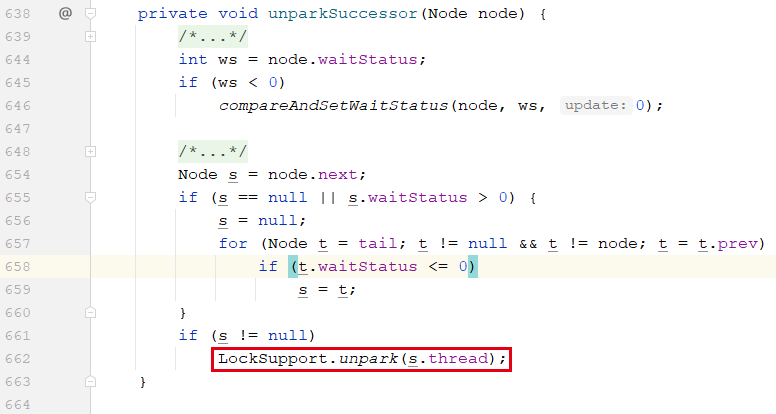
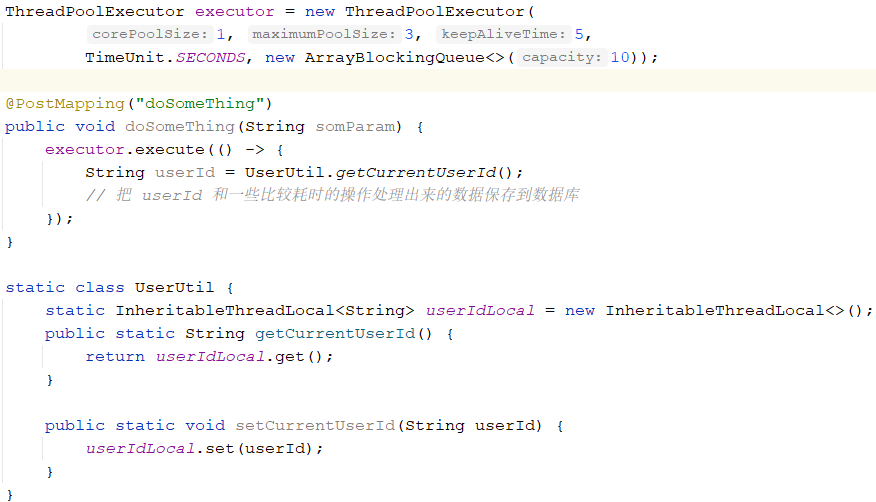
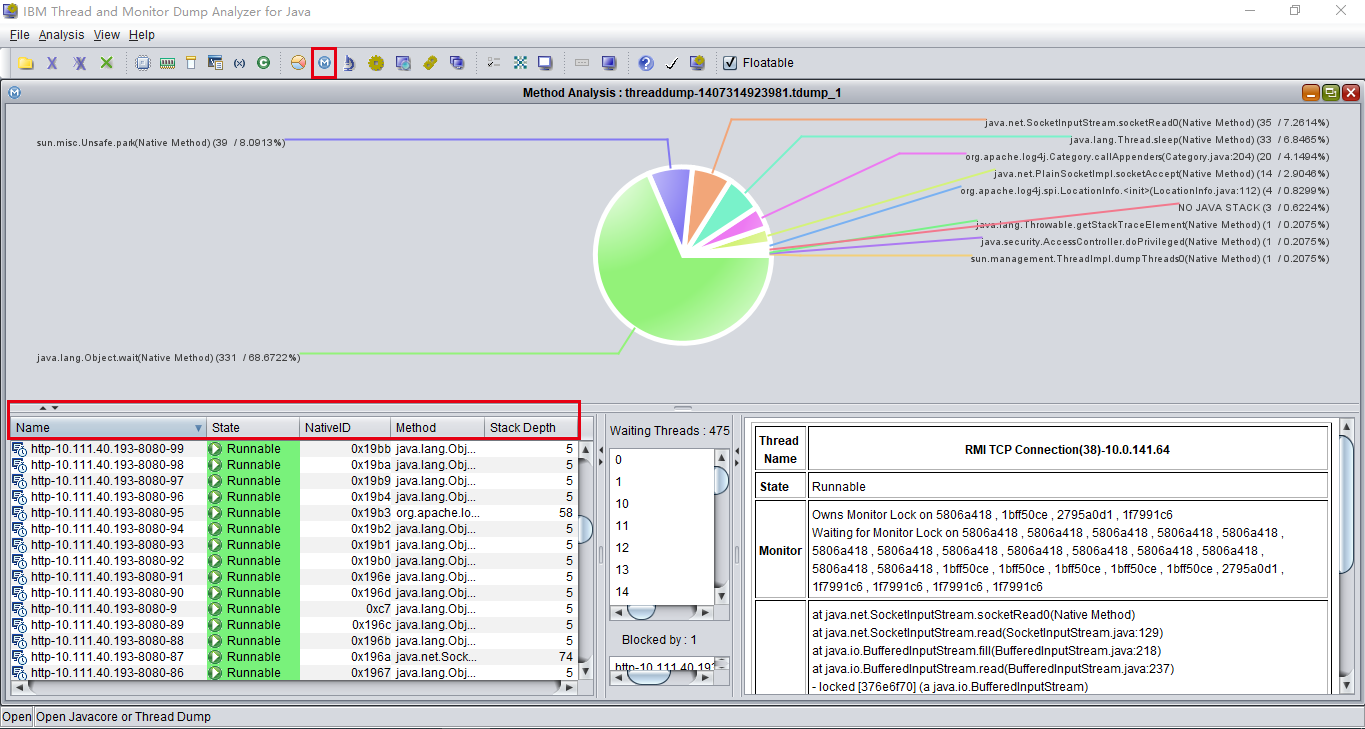
9月5、6号两天,有个古老的应用连续出现频繁的 FullGC,最终OOM。
这个古老应用的框架是十多年前基于 Spring 魔改的,在部署上分为 web、app 两层,web通过 EJB 进行调用app里的服务访问数据库。
这两层访问 Spring 容器里的 Bean 一般都是通过类似下面的写法来获取:
SomeService service = CustAppContextHolder.getContext(contextName).getBean(beanName);
service.doSomething();
// CustAppContextHolder.getContext 的实现大致如下:
public class CustAppContextHolder {
private static Map<String, WeakReference
public static ApplicationContext getContext(String contextName) {
WeakReference<ApplicationContext> weakReference = caches.get(contextName);
ApplicationContext context;
if (weakReference != null && (context = weakReference.get()) != null) {
return context;
} else {
synchronized (CustAppContextHolder.class) {
context = initContext(contextName);
caches.put(contextName, new WeakReference<>(context));
}
}
return context;
}
private static ApplicationContext initContext(String contextName) {
System.out.println("init context:" + contextName);
return null;
}
}