rsync 算法
场景:假设有两台计算机 CA和 CB , CA 上有文件 FA , CB 上有文件 FB , FA 和 FB 是“相似的”。 CA 和 CB 通过低速通信链接连接,现在要把 FA 同步到 FB 上去,如何才能高效同步。
rsync 算法包含下面的步骤:
- CB把 FB 分割成固定大小 S 字节的块,最后一块可能少于 S 字节;
- 对于每个块,CB 计算两个校验和:一个弱的“滚动” 32 位校验和和一个强的 128 位 MD4 校验和。
- CB把这些校验和发给 CA 。
- CA搜索 FA 来查找 S 大小的块,这些块与 CB 的块有相同的弱和强校验和。这可以通过一次遍历来完成,通过利用滚动校验和的特殊属性。
- CA给 CB 发送一序列指令来构建一个 FA 的拷贝。每个指令要么指向 FB 的一个块,要么是文字数据。文字数据只用于发送 FA 的那些不匹配 FB 块的区域。
最终结果是 CB有了 FA 的拷贝,但只发送了那些在 FB 里找不到的数据。
这个算法只要求一个来回,减少了网络延迟。
这个算法的最重要的细节是滚动校验和 和 associated multi-alternate search mechanism which allows the all-offsets checksum search to proceed very quickly.
这里说到的多选择搜索机制,在实现时用HashMap + List。
算法图示
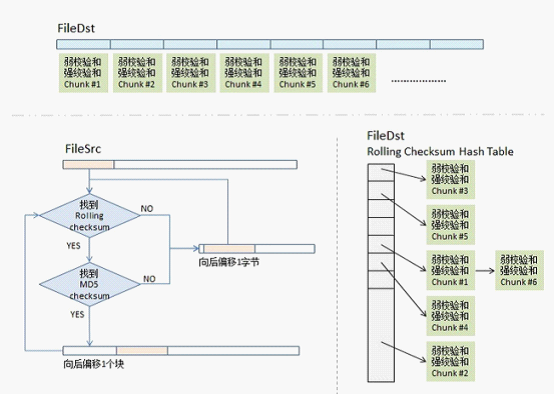
红色的是匹配的块,白色的是实际传输的内容。

滚动校验和
rsync算法使用的弱滚动校验和 须具有非常廉价地根据 X1 .. Xn 和字节值 X1 和 Xn +1 快速计算 X2 .. Xn+1 的校验和的性质。
rsync算法使用弱校验和算法是由 Mark Adler 发明的adler-32 校验和。校验和定义如下:

实现
在实现时,MD5 算法在 Java 里是现成的,滚动校验和也是不难实现。网上其他的博客提到在计算块的滚动校验和时, a 的初始值是 1 ,在我实现时发现那是错的,rsync 的报告文档没说要这样,报告给出的算法公式也没要求,误导我费了不少时间。
在实现过程中,我觉得比较难的在于 根据 checksum 流计算 diffitem 流,也是我要在这里想说的。
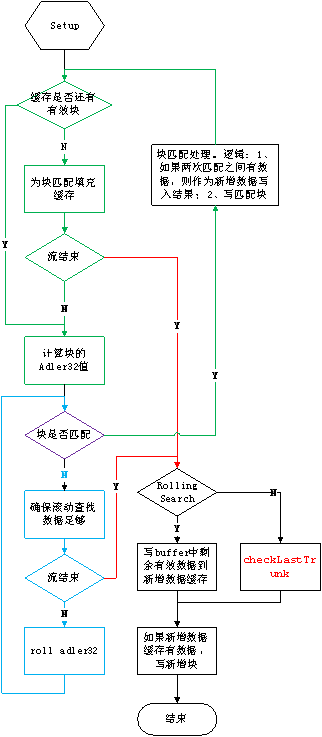
下面这两个图所表示的是基于避免把整个文件读入内存实现的,如果不考虑内存占用,把整个文件读入内存,只需要看第 2 张流程图。在把文件部分读入内存时,第 2 张图是第 1 张图红色字体部分的逻辑。
在实现有两个缓存:
buffer:缓存,容量是块的N倍,直接使用数组。
outBuffer:新增数据块的缓存,是ByteArrayOutputStream的实例。
还有一些int类型的充当指针的变量。
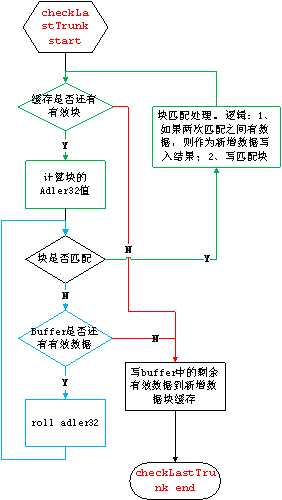
流程图说明:
确保滚动查找数据足够: 判断缓存里是否还有有效的数据,并返回boolean 值表示流是否结束。如果有,返回 false ,如果没有,调用 为块匹配填充缓存,并返回调用结果。
为块匹配填充缓存: 整理并填充缓存,返回boolean 值表示流是否结束。首先把 roll 过的不属于当前块的数据写入新增数据缓存,然后把当前块拷贝到缓存的首部,然后从文件流读取数据填充剩余的缓存空间,并返回表示流是否结束的 boolean 值。
具体源代码见github : https://github.com/wen866595/jrsync
参考资料
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。
