一、问题
一个 8×8 的棋盘,希望往里放 8 个棋子,每个棋所在的行、列、对角线上都不能有其他棋子。找出所有满足要求的布局。
二、分析与解
首先画出下面这样一个棋盘:
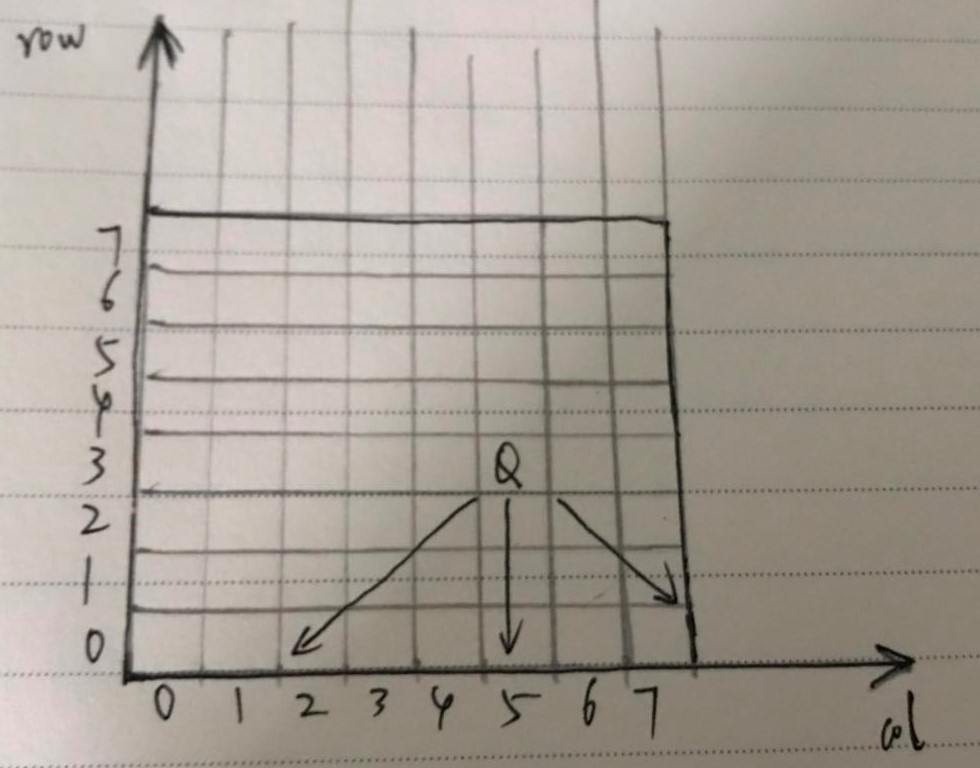
行、列的下标都是从 0 开始。
逐行摆放棋子,比如当前要摆放第 R 行的棋子时,认为 0 至 R-1 行的棋子是符合要求的,那么对于第 R 行,尝试把棋子摆放到第 C 列,检测是否满足要求,如果满足则继续下一行摆放下一行,不满足则则尝试放至 C+1 列。如果摆放到了第 8 行,则认为得到了一个解。
检测算法:从上图可以看出,只需要检查三种场景,对于位置(row, col):
- 左下对角线;该对角线上的点符合
col >= 0 && (row--, col--)。 - 垂直列;(row–, col), 行 渐减,列不变。
- 右下对角线。该对角线上的点符合
col < 8 && (row--, col++)。