并发
线程数 = CPU可用核心数 / ( 1 – 阻塞系数 )
阻塞系数的取值在 0 - 1 之间,计算密集型任务的阻塞系数是 0,IO 密集型任务的阻塞系数接近于 1。
构建计算密集型并发应用程序的几点经验:
* 子任务的划分数不少于处理器核心数;
* 线程数多于处理器核心数对性能提升毫无帮助;
* 在子任务划分超过一定数量之后,再增加子任务划分数对于性能的提升将十分有限。
保持一个合理的划分数,并使所有处理器核心都有足够的工作量才是关键。
应该尽可能地提供共享不可变性,否则就应该遵循隔离可变性原则,即保证总是只有一个线程访问可变变量。
开多少个线程以及如何拆分问题都会影响到你的并发应用程序的性能,还要权衡每个子任务的工作负载和划分开销。
并发编程的三种模式
并发编程的难点就在于对状态的处理,这三种模式是按照对状态的不同处理方式来划分的。
-
共享可变性:允许变量在可控模式下被所有线程修改。为了使用共享可变性,必须保证不会有两个线程同时修改同一个字段,并且对多个字段的修改必须满足一致性原则。这是一种苦逼模式,直接通过 JUC 包里的工具来实现的并发编程一般都属于这种模式。
-
隔离可变性:变量是可变的,但在任意时刻只有不超过一个线程可以看到该变量。 Actor 是这种模式的一个典型实现。可变状态封装在 Actor 内部,不同 Actor 之间通过消息传递进行通信、协作。由于 Actor 是单线程执行的(Actor 是比线程更轻量级的可执行单元),所以只有一个线程能修改状态,所以 Actor 内部不需要进行显式的同步。
-
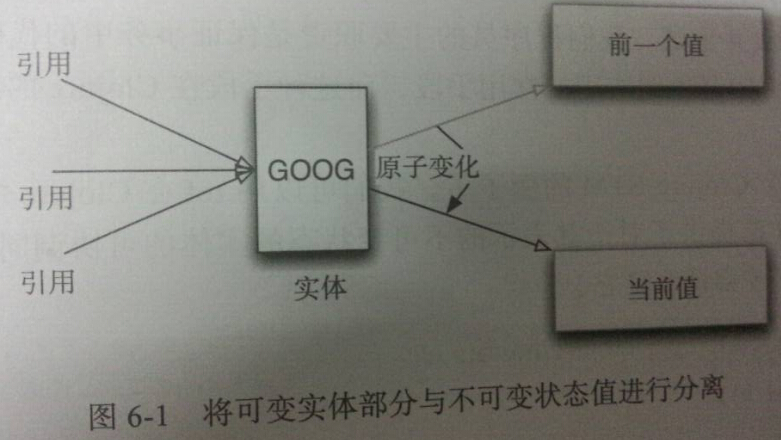
纯粹不可变性:所有事物都是不可变的。STM(soft transaction memory,软件事务内存)是这种模式的典型。在这种模式下,一个对象分为两部分:实体和不可变的状态值。对象的状态值的改变是在事务内进行,成功就提交事务,其他线程可以看到最新的值;如果失败了会回滚,事务会重做。这也就要求事务内的动作是无副作用(比如没有IO操作)、幂等的(做一次与做两次的结果是一样的)。

欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。
