公司的DBA要求把他们固化的执行计划改用 Oracle hint 来实现,正好了解下平时没注意去用的 hint。
优化方式
Oracle的优化器有两种优化方式:
-
基于规则的优化方式(Rule-Based Optimization,简称为RBO) :优化器在分析 SQL 语句时,所遵循的是 Oracle 内部预定的一些规则。比如我们常见的,当一个
where子句中的一列有索引时去走索引。 -
基于代价的优化方式(Cost-Based Optimization,简称为CBO) ;它是看语句的代价(Cost),这里的代价主要指Cpu和内存。优化器在判断是否用这种方式时,主要参照的是表及索引的统计信息。统计信息给出表的大小、有少行、每行的长度等信息。这些统计信息起初在库内是没有的,是做 analyze 后才出现的,很多的时侯过期统计信息会令优化器做出一个错误的执行计划,因些应及时更新这些信息。
hint 也不例外,除了 /*+ rule */ 其他的都是 CBO 优化方式 。
优化模式
优化模式包括 Rule、Choose、First rows、All rows 四种方式:
- Rule:基于规则的方式。
- Choolse:默认的情况下 Oracle 用的便是这种方式。指的是当一个表或或索引有统计信息,则走 CBO 的方式,如果表或索引没统计信息,表又不是特别的小,而且相应的列有索引时,那么就走索引,走 RBO 的方式。
- First Rows:它与 Choose 方式是类似的,所不同的是当一个表有统计信息时,它将是以最快的方式返回查询的最先的几行,从总体上减少了响应时间。
- All Rows:也就是我们所说的 Cost 的方式,当一个表有统计信息时,它将以最快的方式返回表的所有的行,从总体上提高查询的吞吐量。没有统计信息则走 RBO 的方式。
hint
hint 语法
: {DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */
多个hint之间需要用空格分开,如果没有指定正确的hint,oracle讲忽视该hint,没有任何错误提示。
我们可以使用注释(comment)来为一个语句添加 hints,一个语句块只能有一个注释,而且注释只能放在 SELECT,UPDATE 或 DELETE 关键字的后面。
对于所有 OLTP 数据库,建议仅仅是使用 parallel hint,而不是在表或系统级别开启并行:alter table customer parallel degree 35; — 对 OLTP 不推荐。
所有全表扫描的语句,都可以添加 parallel hint 来获得并行查询的好处:select /*+ FULL(emp) PARALLEL(emp, 35) */ from emp;
上面的语句:
- 注意
/*+,*与+之间不能有空格,要连着写; FULL(emp)表示对表emp执行全表扫描,如果是多表关联查询,则每个表必须分开写;emp是表名,如果使用了别名,则必须用别名,如果是多表关联查询,则每个表必须分开写;PARALLEL(emp, 35)提示数据库在表emp上开启35个并行线程来执行;- 并行度可以采用默认值,让数据库去决定,如:
PARALLEL(employee_table, DEFAULT, DEFAULT);
并行执行原理,来自 Oracle parallel hint tips:
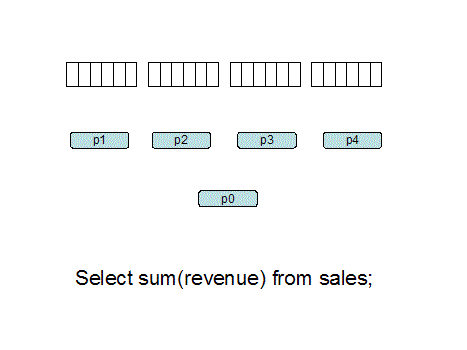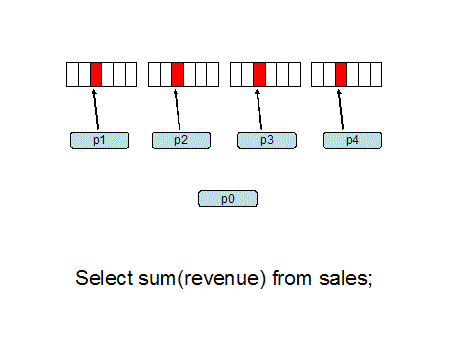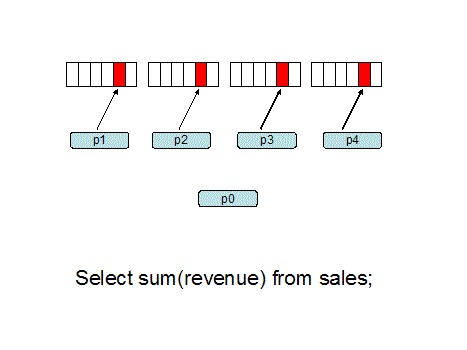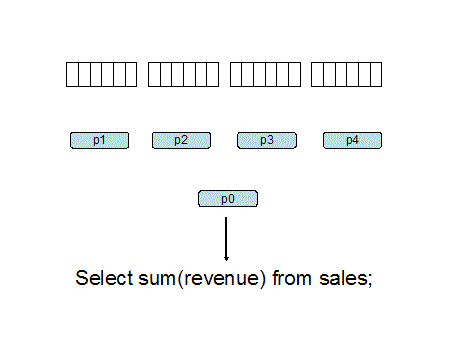
并行执行对于操作大量的数据是很有必要的,对比了 DBA 给出的执行计划与自己加了并行 hint 之后的执行计划,没什么区别。
常用 hint
来自:Oracle优化全攻略一(Oracle SQL Hint) 。
前10个比较常用, 前3个最常用(注:仍然是索引、驱动表、并行)。
-
/*+ INDEX */和/*+ INDEX(TABLE INDEX1, index2) */和/*+ INDEX(tab1.col1 tab2.col2) */和/*+ NO_INDEX */和/*+ NO_INDEX(TABLE INDEX1, index2) */表明对表选择索引的扫描方法。 第一种不指定索引名是让 oracle 对表中可用索引比较并选择某个最佳索引;第二种是指定索引名且可指定多个索引; 第三种是 10g 开始有的,指定列名,且表名可不用别名;第四种即全表扫描; 第五种表示禁用某个索引,特别适合于准备删除某个索引前的评估操作。如果同时使用了INDEX和NO_INDEX则两个提示都会被忽略掉。 -
/*+ ORDERED */:FROM子句中默认最后一个表是驱动表,ORDERED将from子句中第一个表作为驱动表。特别适合于多表连接非常慢时尝试。 -
/*+ PARALLEL(table1,DEGREE) */和/*+ NO_PARALLEL(table1) */:该提示会将需要执行全表扫描的查询分成多个部分(并行度)执行, 然后在不同的操作系统进程中处理每个部分。该提示还可用于DML语句。如果 SQL 里还有排序操作,进程数会翻倍,此外还有一个一个负责组合这些部分的进程。NO_PARALLEL是禁止并行操作。 -
/*+ FIRST_ROWS */和/*+ FIRST_ROWS(n) */:表示用最快速度获得第1/n行, 获得最佳响应时间,使资源消耗最小化。在update和delete语句里会被忽略, 使用分组语句如group by/distinct/intersect/minus/union时也会被忽略。 -
/*+ RULE */:对语句块选择基于规则的优化方法。 -
/*+ FULL(TABLE) */:对表选择全局扫描的方法。 -
/*+ LEADING(TABLE) */:类似于ORDERED提示,将指定的表作为连接次序中的驱动表。 -
/*+ USE_NL(TABLE1,TABLE2) */:将指定表与嵌套的连接的行源进行连接,以最快速度返回第一行再连接,与USE_MERGE刚好相反。 -
/*+ APPEND */和/*+ NOAPPEND */:直接插入到表的最后,该提示不会检查当前是否有插入操作所需的块空间而是直接添加到新块中,所以可以提高速度。 当然也会浪费些空间,因为它不会使用那些做了delete操作的块空间。NOAPPEND提示则相反,所以会取消PARALLEL提示的默认APPEND提示。 -
/*+ USE_HASH(TABLE1,table2) */:将指定的表与其它行源通过哈希连接方式连接起来,为较大的结果集提供最佳响应时间。 类似于在连接表的结果中遍历每个表上每个结果的嵌套循环,指定的hash表将被放入内存,所以需要有足够的内存(hash_area_size或pga_aggregate_target)才能保证语句正确执行,否则将在磁盘里进行。 -
/*+ USE_MERGE(TABLE) */:将指定的表与其它行源通过合并排序连接方式连接起来,特别适合于那种在多个表大量行上进行集合操作的查询,它会将指定表检索到的的所有行排序后再被合并,与USE_NL刚好相反。 -
/*+ ALL_ROWS */:表明对语句块选择基于开销的优化方法,并获得最佳吞吐量,使资源消耗最小化, 可能会限制某些索引的使用。 -
/*+ CLUSTER(TABLE) */:提示明确表明对指定表选择簇扫描的访问方法。如果经常访问连接表但很少修改它,那就使用集群提示。 -
/*+ INDEX_ASC(TABLE INDEX1, INDEX2) */:表明对表选择索引升序的扫描方法。从8i开始,这个提示和INDEX提示功能一样,因为默认 oracle 就是按照升序扫描索引的,除非未来 oracle 还推出降序扫描索引。 -
/*+ INDEX_COMBINE(TABLE INDEX1, INDEX2) */:指定多个位图索引,对于B树索引则使用INDEX这个提示,如果INDEX_COMBINE中没有提供作为参数的索引,将选择出位图索引的布尔组合方式。 -
/*+ INDEX_JOIN(TABLE INDEX1, INDEX2) */:合并索引,所有数据都已经包含在这两个索引里,不会再去访问表,比使用索引并通过rowid去扫描表要快 5 倍。 -
/*+ INDEX_FFS(TABLE INDEX_NAME) */:对指定的表执行快速全索引扫描,而不是全表扫描的办法。要求要检索的列都在索引里,如果表有很多列时特别适用该提示。 -
/*+ NO_EXPAND */:对于WHERE后面的OR或者IN-LIST的查询语句,NO_EXPAND将阻止其基于优化器对其进行扩展,缩短解析时间。 -
/*+ CACHE(TABLE) */和/*+ NOCACHE(TABLE) */:当进行全表扫描时,CACHE提示能够将表全部缓存到内存中,这样访问同一个表的用户可直接在内存中查找数据。比较适合数据量小但常被访问的表,也可以建表时指定cache选项这样在第一次访问时就可以对其缓存。NOCACHE则表示对已经指定了CACHE选项的表不进行缓存。 -
/*+ INDEX_SS(TABLE INDEX1,INDEX2) */:指示对特定表的索引使用跳跃扫描,即当组合索引的第一列不在where子句中时,让其使用该索引。 -
/*+ PUSH_SUBQ */:当SQL里用到了子查询且返回相对少的行时,该提示可以尽可能早对子查询进行评估从而改善性能,不适用于合并连接或带远程表的连接。
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。
