快速排序也是基于分治模式的,对于规模为n的数组,最坏情况运行时间是O(n^2),平均运行时间是O(lg(n))。
对数组A[p…r]排序的分治过程的三个步骤:
- 分解:数组A[p…r]被划分成两个(可能空)子数组A[p…q-1]和A[q+1…r],使得A[p…q-1]中的每个元素都小于等于A[q],而且小于等于A[q+1…r]中的元素。下标q也在这个划分过程中计算。
- 解决:通过递归调用快速排序,对子数组A[p…q-1]和A[q+1…r]排序。
- 合并:因为两个子数组是就地排序,将他们合并不需要操作:整个数组A[p…r]已经排序。
从上面的步骤可以看到,快速排序的关键在划分子数组,且每次划分都产生一个元素,它所在的位置就是它最终的位置。
实现
func quickSortRecur(arr []int, low, high int) {
if low < high {
//p := hoarePartition(arr, low, high)
p := partition(arr, low, high)
quickSortRecur(arr, low, p-1)
quickSortRecur(arr, p+1, high)
}
}
func partition(arr []int, low, high int) int {
v := arr[high]
l, h := low-1, low
for ; h < high; h++ {
if arr[h] < v {
l = l + 1
util.Swap(arr, l, h)
}
}
l = l + 1
util.Swap(arr, l, high)
return l
}
func hoarePartition(arr []int, low, high int) int {
l, r := low+1, high
v := arr[low]
for {
for ; l < r && arr[l] < v; l++ {
}
for ; r >= l && arr[r] >= v; r-- {
}
if l < r {
util.Swap(arr, l, r)
l, r = l+1, r-1
} else {
util.Swap(arr, r, low)
return r
}
}
}
说明
partition函数
对于上面的partition函数的划分过程,是把要排序的数组部分arr[low...high]先分成4个部分,以从左往右的方向看,l是指向小于pivot value值的子数组的最后一个元素的指针,h是指向大于等于pivot value值的子数组最后一个元素的指针:
- pivot value,初始值为arr[high],只有一个元素,放在数组的第一个或最后一个位置上。
- 小于pivot value的子数组,初始值为空,范围为arr[0, l]。
- 大于pivot value的子数组,初始值为空,范围为arr[l, h]。
- 未排序的子数组,初始值为arr[low, high-1]。
下图展示了划分过程,它的指针与函数变量的对应关系: i - l, j - h, p - low, r - high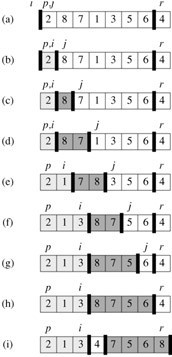
hoarePartition函数
与前面的partition函数类似,也是把要排序的数组划分为4个子数组,只不过l、h指针是相向而行,而partition函数的指针l、h指针是通向前行。
关于分区函数
前面的分区函数都是选择最低位或最高位元素作为哨兵元素,这在数组有序或逆序的极端情况下是很糟糕的,可能导致划分的元素总是处于第一个或最后一个,而不能尽可能平均的划分。
一些改进的方法是取中间的元素或随机取一个元素作为哨兵。
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。
