一、Disruptor 是什么?
Disruptor 是一个高性能异步处理框架,也可以认为是一个消息框架,它实现了观察者模式。
Disruptor 比传统的基于锁的消息框架的优势在于:它是无锁的、CPU友好;它不会清除缓存中的数据,只会覆盖,降低了垃圾回收机制启动的频率。
这个解读是在最新版 3.1.1 的源码上进行。
关于Disruptor的更多介绍可见: http://ifeve.com/disruptor/
二、Disruptor 为什么快
- 不使用锁。通过内存屏障和原子性的CAS操作替换锁。
-
缓存基于数组而不是链表,用位运算替代求模。缓存的长度总是2的n次方,这样可以用位运算
i & (length - 1)替代i % length。 -
去除伪共享。CPU的缓存一般是以缓存行为最小单位的,对应主存的一块相应大小的单元;当前的缓存行大小一般是64字节,每个缓存行一次只能被一个CPU核访问,如果一个缓存行被多个CPU核访问,就会造成竞争,导致某个核必须等其他核处理完了才能继续处理,响应性能。去除伪共享就是确保CPU核访问某个缓存行时不会出现争用。
-
预分配缓存对象,通过更新缓存里对象的属性而不是删除对象来减少垃圾回收。
三、Disruptor 架构
核心类和接口
EventHandler:用户提供具体的实现,在里面实现事件的处理逻辑。Sequence:代表事件序号或一个指向缓存某个位置的序号。WaitStrategy:功能包括:当没有可消费的事件时,根据特定的实现进行等待,有可消费事件时返回可事件序号;有新事件发布时通知等待的SequenceBarrier。Sequencer:生产者用于访问缓存的控制器,它持有消费者序号的引用;新事件发布后通过WaitStrategy通知正在等待的SequenceBarrier。SequenceBarrier:消费者关卡。消费者用于访问缓存的控制器,每个访问控制器还持有前置访问控制器的引用,用于维持正确的事件处理顺序;通过WaitStrategy获取可消费事件序号。EventProcessor:事件处理器,是可执行单元,运行在指定的Executor里;它会不断地通过SequenceBarrier获取可消费事件,当有可消费事件时调用用户提供的EventHandler实现处理事件。EventTranslator:事件转换器,由于Disruptor只会覆盖缓存,需要通过此接口的实现来更新缓存里的事件来覆盖旧事件。RingBuffer:基于数组的缓存实现,它内部持有对Executor、WaitStrategy、生产者和消费者访问控制器的引用。Disruptor:提供了对RingBuffer的封装,并提供了一些DSL风格的方法,方便使用。
每个事件处理器EventProcessor都持有一个表示它最后处理的事件的序号的Sequence,所以可以用Sequence来代表事件处理器;
下面是Disruptor里事件处理的一个示例图:
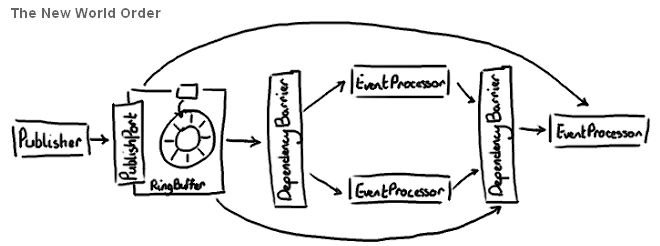
四、实现
Sequence 类
Sequence类表示一个序号,是对long型字段的线程安全的封装,用于跟踪ringBuffer的进度和事件处理器的进度。
支持一些并发操作,包括CAS和有序写。
尝试在volatile字段周围填充内容来避免伪共享,变得更高效。
实现
public class Sequence {
static final long INITIAL_VALUE = -1L;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static {
UNSAFE = Util.getUnsafe();
final int base = UNSAFE.arrayBaseOffset( long[].class );
final int scale = UNSAFE.arrayIndexScale( long[].class );
VALUE_OFFSET = base + (scale * 7);
}
// 15个元素,从0开始,有效值处于第7个,这样前后各有7个long字段填充,
// 8个long型占共用64字节,而当前CPU的缓存行大小也是64字节,这样可以避免对Sequence的读写出现伪共享。
private final long [] paddedValue = new long [15];
// 原子地读
public long get() {
return UNSAFE .getLongVolatile(paddedValue, VALUE_OFFSET);
}
// 原子地写
public void set(final long value) {
UNSAFE.putOrderedLong(paddedValue , VALUE_OFFSET, value);
}
// CAS
public boolean compareAndSet(final long expectedValue, final long newValue) {
return UNSAFE .compareAndSwapLong(paddedValue, VALUE_OFFSET, expectedValue, newValue);
}
public long addAndGet(final long increment) {
long currentValue;
long newValue;
do {
currentValue = get();
newValue = currentValue + increment;
} while (!compareAndSet(currentValue, newValue));
return newValue;
}
// 还有其他一些方法,都是借助 sun.misc.Unsafe 类来实现的。
伪共享
关于伪共享可参考:
- 《剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充》 http://ifeve.com/disruptor-cacheline-padding/
-
《伪共享(False Sharing)》- http://ifeve.com/falsesharing/
Disruptor类
Disruptor类是这个类库的门面,用DSL的形式直观地提供了组装事件回调处理的关系链的功能,并提供获取事件、发布事件的方法,缓存容器生命周期管理。
属性
private final RingBufferringBuffer ; // 核心,绝大多数功能都委托给ringBuffer处理 private final Executor executor ; // 用于执行事件处理器的线程池 private final ConsumerRepository consumerRepository = new ConsumerRepository (); // 事件处理器仓库,就是事件处理器的集合 private final AtomicBoolean started = new AtomicBoolean( false); // 启动时检查,只能启动一次 private ExceptionHandler exceptionHandler; // 异常处理器
设置EventHandler事件处理器
/* * barrierSequences是eventHandlers的前置事件处理关卡,是用来保证事件处理的时序性的关键; * */ EventHandlerGroupcreateEventProcessors( final Sequence[] barrierSequences, final EventHandler [] eventHandlers) { checkNotStarted(); // 确保在容器启动前设置 final Sequence[] processorSequences = new Sequence[eventHandlers.length ]; // 存放游标的数组 final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences); // 获取前置的序号关卡 for ( int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++) { final EventHandler eventHandler = eventHandlers[i]; // 封装为批量事件处理器BatchEventProcessor,其实现了Runnable接口,所以可以放到executor去执行处理逻辑;处理器还会自动建立一个序号Sequence。 final BatchEventProcessor batchEventProcessor = new BatchEventProcessor (ringBuffer , barrier, eventHandler); if (exceptionHandler != null) { // 如果有则设置异常处理器 batchEventProcessor.setExceptionHandler( exceptionHandler); } // 添加到消费者仓库,会先封装为EventProcessorInfo对象(表示事件处理的一个阶段), consumerRepository.add(batchEventProcessor, eventHandler, barrier); processorSequences[i] = batchEventProcessor.getSequence(); } if (processorSequences. length > 0) {// 如果有前置关卡,则取消之前的前置关卡对应的EventProcessor 的 链的终点标记。 consumerRepository.unMarkEventProcessorsAsEndOfChain(barrierSequences); } // EventHandlerGroup是一组EventProcessor,作为disruptor的一部分,提供DSL形式的方法,作为方法链的起点,用于设置事件处理器。 return new EventHandlerGroup (this, consumerRepository, processorSequences); }
这里要注意的是,EventHandler只能在启动前添加。
从代码来看,EventHandler是用户提供的,单纯的的事件处理逻辑的实现,在被添加到消费者仓库之前,它会被封装为一个EventProcessor对象。
RingBuffer 类
属性
首先来看下RingBuffer类的属性:
// 属性的初始化声明
public static final long INITIAL_CURSOR_VALUE = Sequence.INITIAL_VALUE ;
private final int indexMask ;
private final Object[] entries ;
private final int bufferSize ;
private final Sequencer sequencer ;
// 属性的初始化代码
RingBuffer(EventFactory eventFactory,
Sequencer sequencer) {
this.sequencer = sequencer;
this.bufferSize = sequencer.getBufferSize();
if (bufferSize < 1) {
throw new IllegalArgumentException("bufferSize must not be less than 1");
}
if (Integer.bitCount( bufferSize) != 1) {
throw new IllegalArgumentException("bufferSize must be a power of 2");
}
this.indexMask = bufferSize - 1;
this.entries = new Object[sequencer.getBufferSize()];
fill(eventFactory);
}
上这些代码可以看出:
- RingBuffer是基于数组构建的,因为数组是缓存友好的,相邻的元素一般处于同一个缓存块。
-
缓存的大小必须是2的X次方,这是为了用位运算提高性能;由于数组缓存的容量总是有限,当缓存填满后,又要从 下标0 开始填充,如果缓存大小不是2的X次方,那只能用求模运算来获得新下标,所以还有个indexMask 来保存下标掩码;通过与indexMask 进行按位与可以得到一个安全的下标,不再需要进行下标检查,如:
(E)entries[( int)sequence & indexMask ]。
从缓存获取事件
// 从缓存获取指定序号的事件
public E get(long sequence) {
// 这个按位与操作说明了为什么ringBuffer的大小必须是2的n次方:用高效的 按位与 代替 低效的求模操作。
return (E) entries[(int ) sequence & indexMask];
}
发布事件
发布事件有3步:获取新事件的序号,覆盖旧事件,通知等待着。最简单的发布事件形式:
public void publishEvent(EventTranslatortranslator) { final long sequence = sequencer .next(); // 通过生产者序号控制器获取可用序号 translateAndPublish(translator, sequence); // 转换事件到队列缓存并发布事件 } private void translateAndPublish(EventTranslator translator, long sequence) { try { // 发布事件前要先获取对应位置上的旧事件,再用translator把新事件的属性转换到旧事件的属性,从而达到发布的目的。 // 这就是说,Disruptor对于已消费的事件是不删除的,有新事件时只是用新事件的属性去替换旧事件的属性。 // 这带来的一个问题就是内存占用 translator.translateTo(get(sequence), sequence); } finally { sequencer.publish(sequence); // 原子性地更新生产者的序号,并通知在等待的消费者关卡。 } }
需要注意的是,生产者序号控制器与消费者关卡是共用同一个等待策略的,一个Disruptor容器只有一个等待策略实例。
EventProcessor
事件处理器的执行单元。有两个实现:NoOpEventProcessor 和 BatchEventProcessor,其中 NoOpEventProcessor 是不处理事件的,就不关注了。
BatchEventProcessor
Disruptor提供的唯一有用的 EventProcessor 实现类。
Disruptor容器启动时,会调用 ConsumerInfo 的 start方法,如果 ConsumerInfo 封装的是用户提交的 EventHandler 实例,那么会在线程池里运行 EventProcessor,也就是 BatchEventProcessor 实例的 run 方法。
核心run方法
该方法的文档说明提到调用 halt 方法后是可以重新执行这个方法的。
public void run() {
// 确保一次只有一个线程执行此方法,这样访问自身的序号就不要加锁
if (! running.compareAndSet(false, true)) {
throw new IllegalStateException("Thread is already running");
}
sequenceBarrier.clearAlert(); // 清除前置序号关卡的通知状态
notifyStart(); // 声明周期通知,开始前回调
T event = null;
long nextSequence = sequence.get() + 1L; // sequence指向上一个已处理的事件,默认是-1.
try {
while (true ) {
try {
// 从它的前置序号关卡获取下一个可处理的事件序号。
// 如果这个事件处理器不依赖于其他的事件处理器,则前置关卡就是生产者序号;
// 如果这个事件处理器依赖于1个或多个事件处理器,那么这个前置关卡就是这些前置事件处理器中最慢的一个。
// 通过这样,可以确保事件处理器不会超前处理地事件。
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
// 处理一批事件
while (nextSequence <= availableSequence) {
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
// 设置它自己最后处理的事件序号,这样依赖于它的处理器可以它处理刚处理过的事件。
sequence.set(availableSequence);
} catch (final TimeoutException e) {
// 获取事件序号超时处理
notifyTimeout( sequence.get());
} catch (final AlertException ex) {
// 处理通知事件;检测是否要停止,如果非则继续处理事件
if (!running .get()) {
break;
}
} catch (final Throwable ex) {
// 其他异常,用事件处理器处理;然后继续处理下一个事件
exceptionHandler.handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
} finally {
// 声明周期通知,停止事件回调;复位运行状态标志,确保可以再次运行此方法。
notifyShutdown();
running.set(false );
}
}
从 while 循环可以看出,事件处理可以分为三步:
- 从
SequenceBarrier获取获取可以处理的最大事件序号; - 循环处理可处理事件;
- 更新自身的已处理的事件序号,让依赖自身的事件处理器可以继续处理。
sequence .set 和 sequence .get 方法都是原子性地读取、更新序号的,这样就避免了加锁,从而提供性能。
sequenceBarrier .waitFor 最终也会调用 sequence .get 方法。
SequenceBarrier
协作式关卡,用于跟踪生产者游标和依赖的事件处理器的序号的数据结构。有两个实现 DummySequenceBarrier 和 ProcessingSequenceBarrier,类如其名,前者是虚拟的,只有空方法;后者是实用的。
SequenceBarrier接口定义
public interface SequenceBarrier {
// 等待指定的序号变得可消费
long waitFor(long sequence) throws AlertException, InterruptedException, TimeoutException;
// 返回当前可读的游标(一个序号)
long getCursor();
// 当前是否有通知状态给此关卡
boolean isAlerted();
// 通知事件处理器状态发生改变,并保持这个状态直到被清除
void alert();
// 清除当前通知状态
void clearAlert();
// 检查通知状态,如果有异常则抛出
void checkAlert() throws AlertException;
ProcessingSequenceBarrier
生成
ProcessingSequenceBarrier的实例是由框架控制的。
首先在Disruptor类的createEventProcessors方法内:
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences); // 获取前置的序号关卡
RingBufferd 的newBarrier方法:
public SequenceBarrier newBarrier(Sequence... sequencesToTrack) {
return sequencer.newBarrier(sequencesToTrack); // 是通过生产者序号控制器生成的。
}
AbstractSequencer的newBarrier方法。
public SequenceBarrier newBarrier(Sequence... sequencesToTrack) {
return new ProcessingSequenceBarrier(this, waitStrategy, cursor, sequencesToTrack);
}
构造函数
/**
* @param sequencer 生产者序号控制器
* @param waitStrategy 等待策略
* @param cursorSequence 生产者序号
* @param dependentSequences 依赖的Sequence
*/
public ProcessingSequenceBarrier(final Sequencer sequencer, final WaitStrategy waitStrategy,
final Sequence cursorSequence, final Sequence[] dependentSequences) {
this. sequencer = sequencer;
this. waitStrategy = waitStrategy;
this. cursorSequence = cursorSequence;
// 如果事件处理器不依赖于任何前置处理器,那么dependentSequence也指向生产者的序号。
if (0 == dependentSequences. length) {
dependentSequence = cursorSequence;
} else { // 如果有多个前置处理器,则对其进行封装,实现了组合模式。
dependentSequence = new FixedSequenceGroup(dependentSequences);
}
}
获取序号的方法
/**
* 该方法不保证总是返回未处理的序号;如果有更多的可处理序号时,返回的序号也可能是超过指定序号的。
*/
public long waitFor(final long sequence) throws AlertException, InterruptedException, TimeoutException {
// 首先检查有无通知
checkAlert();
// 通过等待策略来获取可处理事件序号,
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence , this);
// 这个方法不保证总是返回可处理的序号
return availableSequence;
if (availableSequence < sequence) {
}
// 再通过生产者序号控制器返回最大的可处理序号
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
WaitStrategy
WaitStrategy定义了一个EventProcessor在Sequence没有可消费事件时的等待策略。
接口定义
public interface WaitStrategy {
/**
* 如果事件处理器不依赖于任何前置处理器,那么cursor与dependentSequence都将指向生产者的序号。
*
* sequence:要获取的序号
* cursor:指向了生产者的Sequence
* dependentSequence:调用者依赖的前置关卡
* barrier:调用者自身,通过调用barrier.checkAlert可以及时响应通知
*/
long waitFor( long sequence, Sequence cursor, Sequence dependentSequence, SequenceBarrier barrier)
throws AlertException, InterruptedException, TimeoutException;
// 当游标前进的时候(有可处理的事件)通知EventProcessor
void signalAllWhenBlocking();
}
实现
BlockingWaitStrategy:没有可消费事件时阻塞等待生产者唤醒。
BusySpinWaitStrategy:忙等策略。
PhasedBackoffWaitStrategy:
TimeoutBlockingWaitStrategy:
YieldingWaitStrategy:通过调用Thread.yield方法来让出CPU,达到等待的目的,等待时长没保证,取决于线程的调度系统。
小结
通过缓冲行填充和适当的封装,Disruptor提供了一个CPU友好、线程安全的序号表示。
通过每个消费者持有自己的事件序号,没有相互依赖的消费者可以并行地处理事件。在消费者之间引入消费者关卡,轻易地实现了消费者之间的前后依赖关系。
对于生产者,即使有多个线程同时访问,由于他们都通过序号器Sequencer访问ringBuffer,Disruptor框架通过CAS取代了加锁和同步块,这也是并发编程的一个指导原则:把同步块最小化到一个变量上。
通过原子读写序号、CAS操作消除了对锁的使用,提高了性能。
Distuptor的一个缺点是内存占用:因为它不清除旧事件数据。
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。

这个同时也能不gc
不清除旧事件数据会导致这些数据仍然存在强引用,有强引用就不能GC,也就导致内存不能释放。
这样做的目的是为了减少垃圾回收,算是以空间换时间的权衡吧。
在高并发的场景,旧事件数据很快就会被新事件数据覆盖,所以不显式清楚也可以的吧?
Disruptor 作为一个队列,也是容器,容器就应该把被删除的元素从容器里移除,防止内存泄漏。这是实现上的严谨性,是保证任何情况都有正确内存回收行为的必要条件。