一个简短的笔记。
Disruptor 快的核心秘诀是:基于数组、空间局部性良好、消除伪共享、无锁、支持批量消费。
1. 基于数组的内存局部性
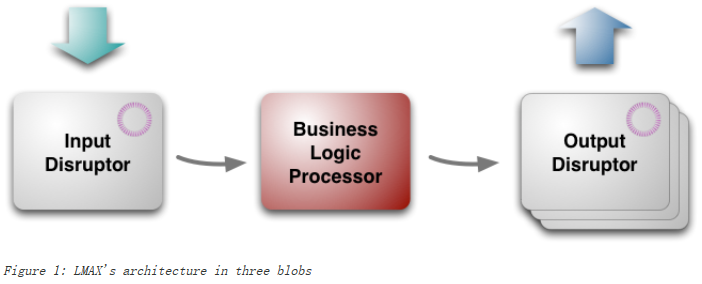
Disruptor 底层是一个固定大小的环形数组,初始化的时候会顺序创建与数组长度一样数量的对象,以便让这些对象在内存上尽量挨着的。
顺序创建与随机创建在内存上的差别可以对比下面两张图(来自极客时间专栏《Java并发编程实战》):
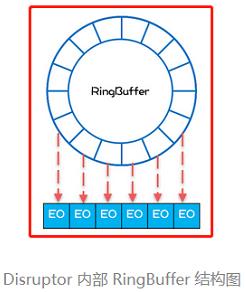
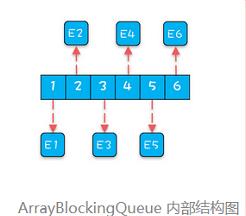
往队列里写入事件时,需要把事件的属性拷贝到这些预创建好的对象里,以保持内存的局部性。
这里的一个隐性要求是:事件的属性应该尽量是基本类型,如果是对象类型,存的是引用,访问引用指向的值时可能就是随机的内存访问。