《Oracle DBA 手记 — 数据库诊断案例与性能优化实践》摘录(P218)
Oracle 数据库中索引的存储结构使用的是 B Tree 的一种变体,称为 B*Tree (B Star Tree),在数据库中存储数据以块为单位。
一些术语:
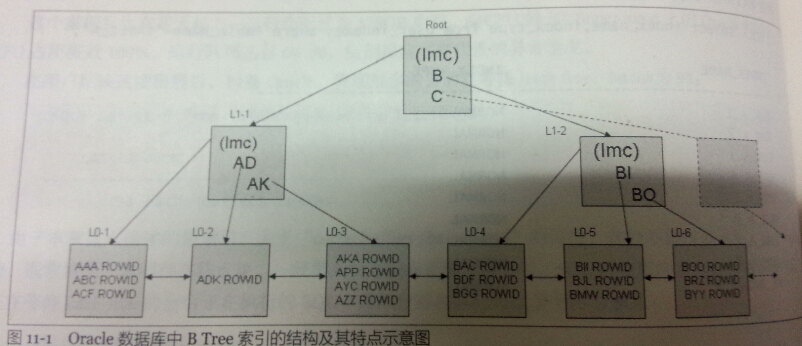
- 节点 M 的深度:从树根节点到节点 M 的最短路径长度。图中根节点 Root 的深度是 0,节点 L1-1 的深度是 1,节点 L0-1 的深度是 2。
- 节点 M 的层数:节点 M 的层数与其深度是相同的。
- 树的高度:树的深度值最大的那个节点,其深度
+1即为树的高度。图中树的高度为 3。
Oracle 数据库的索引有下列的特点:
-
存储索引数据的块,称为 B Tree 的节点。有三种类型的节点,根(root)节点、分支(branch)节点和叶(leaf)节点。高度为 1 的索引只有根节点,这时索引只有唯一的叶节点,也同时是根节点;高度大于 1 时,根节点与分支节点具有完全相同的结构,也就是说这时,根节点也是分支节点。分支节点索引块存储的数据主要包括:索引值、键值对应的下一级节点块地址、还有一个称为“kdxbrlmc” 的指针,也就是图中的 “lmc”,这个指针就是当前枝节点中最小的索引值还小的下一级节点块的数据块地址(DBA)。叶节点索引块存储的数据主要是索引值以及对应的 rowid,和当前节点的前后两个节点的数据块地址。
-
索引的根节点,总是紧跟在索引段头的后面的一个数据块。比如某个索引的段头为
7/817(相对文件号/块号),那么根节点就是7/7818。Oracle 在执行 SQL 时,直接从数据字典得到段头位置后就能定位到根节点。这可以减少逻辑读。 -
索引是始终平衡的。
-
索引的每一个叶节点,有两个指针,分别指向比当前节点最小索引值还小的叶节点块的地址,以及比当前节点最大索引值还大的叶节点块地址。通过这两个指针,把所有的叶节点串起来,形成一个双向链表。顺序遍历这个链表即可得到有序的数据。
-
索引的分枝节点块所存储的索引值,并不是完整的索引值,而只是整个索引值的前缀,只要能够区分其大小就可以。比如图中 L1-1 分枝节点,有两个值, AD 和 AK,其指向的叶节点起始索引值为 ADK 以及 AKA,但是其前缀 AD 和 AK 即可以区分其大小。这种设计能够使分枝节点存储更多的条目,减少了分枝节点数,特别是在多列复合索引中,对于很大的表,甚至可以减少 B Tree 的高度。
-
B Tree 索引不对 NULL 值进行索引,对于某一列,索引的所有列的值都是 NULL 值时,该行不能被索引。复合索引只要有一列不为 NULL 是可以被索引的。
Oracle 如何扫描索引
Oracle 在扫描 B Tree 索引时可以从索引的左端扫描到右端或者从右端扫描到左端。对于索引唯一扫描,两者没啥区别,两者的区别主要体现在索引范围扫描,包括索引跳跃扫描(INDEX SKIP SCAN)和索引全扫描(INDEX FULL SCAN)。
一般情况下,索引都是从左端扫描到右端,只有在使用了如 INDEX_DESC 这样的 HINT 或使用 ORDER BY DESC (如果是降序索引,则是 ORDER BY)时才会从右端扫描到左端。
Oracle 在扫描索引时,首先从数据字典得到索引段头块的位置,这个块地址 +1 即得到索引的 root block 块地址。通过 root block 定位到 branch block,再通过 branch block 定位到下一级 branch block,直至最后定位到 leaf block。然后从定位到的 leaf block 根据确定的扫描方向,从左往右扫描或从右往左扫描。
在从索引中扫描到数据,包括 rowid 之后,如果所获得的数据已经满足需要,则将数据返回给上一步,比如直接返回给客户端,否则必须根据 rowid ,再从表里获得数据返回给上一步。
常见的几种索引扫描方式:
- INDEX UNIQUE SCAN:索引唯一扫描,出现在索引的“所有列”上使用“等于”条件的 SQL 中,最多返回一行结果。
- INDEX RANGE SCAN:索引范围扫描,出现在非唯一索引的前缀或所有列上使用任意比较条件的 SQL 中。
- INDEX FULL SCAN:索引全扫描,按顺序扫描索引中的所有叶节点块。
- INDEX FAST FULL SCAN:索引快速全扫描,并行读取多个数据块进行扫描,扫描得到的结果是无序的。
- INDEX SKIP SCAN:索引跳跃扫描,出现在复合索引中,对非前缀列上使用任意比较条件的 SQL 中。Oracle 在扫描时,会扫描所有的 branch block,然后对 branch block 中的每一个值,都会去扫描 leaf block。适合于复合索引的前缀列不同值个数很少的情况,否则其扫描成本非常高。
除了第四种都是对索引进行单块读,第四种是进行多块读。前三种扫描方式,其结果是按值的大小顺序返回的,因此在需要顺序结果(比如 ORDER BY)时,能够避免在这些列上进行排序。
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。
