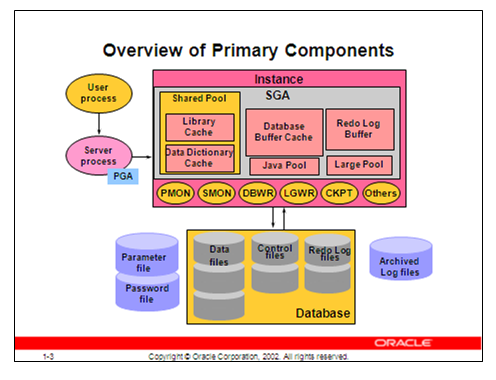
引言
Oracle 使用两种引擎来处理 PL/SQL 代码。所有存储过程的代码由 PL/SQL 引擎处理,所有的 SQL 由 SQL 语句执行器/SQL 引擎处理。
在两个引擎直间的上下文切换会带来开销。如果 PL/SQL 代码在一个集合上循环,为集合里的每个元素执行同样的 DML 操作,那么可以通过一次 bulk 绑定整个集合到 DML 语句上以减少上下文切换。
BULK COLLECT
Bulk 绑定可以在从查询里加载数据集时提升性能。BULK COLLECT INTO 把查询的数据结构化绑定到集合上。
CREATE TABLE bulk_collect_test AS
SELECT owner,
object_name,
object_id
FROM all_objects;
-- 使用
DECLARE
TYPE t_bulk_collect_test_tab IS TABLE OF bulk_collect_test%ROWTYPE;
l_tab t_bulk_collect_test_tab := t_bulk_collect_test_tab();
l_start NUMBER;
BEGIN
SELECT *
BULK COLLECT INTO l_tab
FROM bulk_collect_test;
END;
集合是维护在内存里的,因此从一个大查询里做 bulk collect 会对性能有显著的影响。事实上,你不应该以这样的方式直接使用 bulk collect 。应当使用 LIMIT 子句限制返回的行数,这让你得到 bulk 方式的好处,又不会占用大量的服务器内存。