原文介绍了 LMAX 支持高性能、低延迟的架构,还介绍了 Disruptor 这个框架的设计缘由。
LMAX 用 3Ghz 的 CPU 单线程处理达到 600w TPS,意味着要在 500 个时钟周期内处理完一个事务。(dual-socket quad-core,32GB RAM)
LMAX 整体架构:
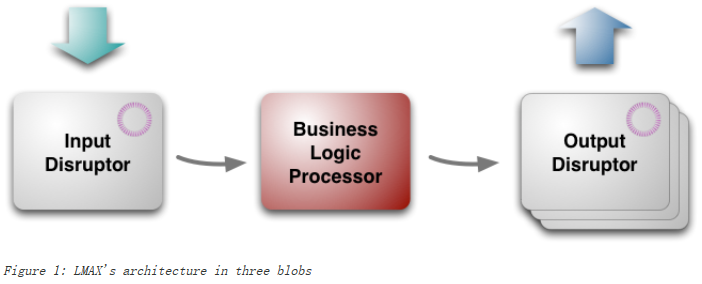
Business Logic Processor,BLP
只是简单的 Java 代码,不依赖于任何框架。单线程执行,全内存操作, 顺序地获取输入的消息。
要操作的数据全在内存里。好处有两点:快 和 简化了编程(没有对象/关系映射)。
用 Event Sourcing 事件溯源机制来保证 BLP 的状态是可以重建的,输入事件由 input disruptor 来进行持久化。事件溯源机制可以采用快照的方式来缩短重建需要的时间。
LMAX 采用多个 BLP 同时处理同样的事件(两个在同一个数据中心,第三个在灾备中心),但只有一个 BLP 的输出是有效的。当存活的 processor 失败时,系统切换到另一个。
事件溯源的另一个好处是诊断方便,可以把事件拷贝到开发环境进行重放。
Tuning performance
性能调优的一个重要技术是 性能测试。
编写正确的性能测试代码比编写正确的生产代码还难。
编程模型
这种风格的处理给编写和组织业务逻辑带来一些约束。
首先要提取出任何与外部服务交互的部分,业务逻辑里不能调用任何外部服务。
需要实现为:事件驱动、异步风格的。
错误处理:对于基于数据库的处理,出错时只需回滚事务就行。
LMAX 的基于内存的数据结构在多个事件之间是持续的,如果出错了可能导致不一致的状态。然而没有自动回滚的设施。
结果是:LMAX 团队花费大量的精力来保证输入事件是完全合法的,在对内存的c持续状态做任何修改之前。测试是找出这类问题的关键工具。
Input and Output Disruptor
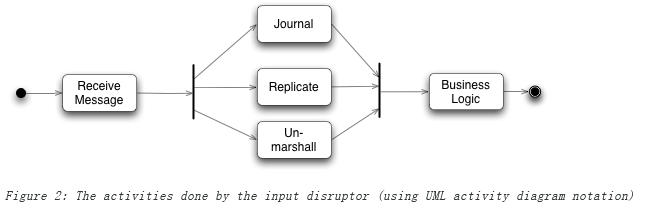
上图 replicate/journal 涉及 IO 操作,是相对较慢的。上述三者都需要在 BLP 处理消息之前完成,适合采用并发。
LMAX 设计了 Disruptor 来完成上面的并发,底层是一个 环形缓冲。
每个生产者和消费者都有一个 sequence counter 来指示它当前处理的槽。
每个生产者和消费者都只写自己的 sequence counter,但可以读其他人的 sequence counters。
生产者可以观察消费者的 sequence counter 来保证要写入的槽是已消费或空闲的,消费者可以观察生产者的 sequence counter 来保证要读取的槽是有效的。
disruptor 的这种设计支持批量消费事件,有利于落后的消费者快速跟上,降低总体的延迟。
环形缓冲一般很大,大小为 2 的幂以高效地取模。sequence counter 使用 64位的长整型数字,单调递增。
Queues and their lack of mechanical sympathy
Actor模型依赖于独立、活跃对象自身的线程,通过 queue 来进行通信。
相对于 CPU,访问主存是个很慢的操作,因此尽量让要操作的数据位于高速缓存。
在高并发的情况下对队列的访问会成为瓶颈。往队列加入或移除元素都需要对队列进行修改,这就带来写竞争。为了解决写竞争,队列通常使用锁,一旦引入锁,可能导致内核的上下文切换,当上下文切换发生时,处理器核可能丢失高速缓存里的数据。
LMAX 团队得到的结论是:为了得到最好的缓存行为,设计里,对内存任何位置应当只有一个处理器核会进行 写。多个读者是 ok 的,处理器核通常使用特定的高速通道来连接他们的高速缓存。队列不满足单个写者的原则。
这个结论引导 LMAX 团队得到一组推论:首先指导了 disruptor 的设计,它严格遵守单个写者的约束;第二引向了探索用单线程处理业务逻辑的设计。
单线程工作的精髓是:确保只有一个线程运行在一个处理器核,高速缓存 warn up,内存访问尽可能落到高速缓存而不是主存。这意味着代码和工作的数据集需要尽可能一致地访问,同时保持代码和数据对象尽量小以允许他们作为高速缓存的一个单元进行置换,可以简化高速缓存管理、提升性能。
Should you use this architecture
LMAX 处理的事件之间是有前后顺序影响的。如果事务之间是独立的,使用独立的处理器核去并行处理是更有吸引力的。
欢迎关注我的微信公众号: coderbee笔记 。
