《深入理解Java虚拟机:JVM高级特性与最佳实践》-笔记
一、概述
垃圾回收,Garbage Collection,简称GC。
GC需要完成三件事:
- 哪些内存需要回收?
- 什么时候回收?
- 如何回收?
继续阅读
《深入理解Java虚拟机:JVM高级特性与最佳实践》-笔记
垃圾回收,Garbage Collection,简称GC。
GC需要完成三件事:
BufferedReader 提供了一个lines()方法用于返回文本行的流Stream<String>。 Files类也提供了一个同名的方法lines(Path, Charset)返回文本行的流,在返回的流上结合Lambda可以进行一序列便捷的处理。
System.out.println("\nBufferedReader.lines");
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(new FileInputStream("text.txt")));
bufferedReader
.lines()
.filter(line -> line.length() > 2)
.filter(line -> line.matches("\\d+"))
.forEach(line -> System.out.println(line));
System.out.println("\nFiles.lines");
Stream<String> stream = Files.lines(Paths.get("text.txt"), Charset.forName("utf8"));
stream.filter(line -> line.length() > 5)
.forEach(line -> System.out.println(line));
在Java SE 8 b116的实现里,Stream是继承自AutoCloseable接口,所以可以结合try-with-resourse机制来确保资源的关闭。
Files新增了3个方法用于遍历目录:Files.list(Path), Files.walk(Path, int, FileVisitOption...), Files.walk(Path, FileVisitOption...)。
Files.list方法只遍历当前目录下的文件和目录,Files.walk方法遍历指定目录下的所有文件和目录,除非指定了最大深度。
第一个walk方法的int类型参数用于指定遍历的最大深度。
System.out.println("\nFiles.list");
Files.list(Paths.get("."))
.filter(path -> !path.toString().endsWith(".iml"))
.forEach(path -> System.out.println(path));
System.out.println("\nFiles.walk");
Files.walk(Paths.get("."), 3, FileVisitOption.values())
.filter(path -> path.toString().startsWith(".\\src"))
.forEach(path -> System.out.println(path));
System.out.println("\nFiles.walk 2");
Files.walk(Paths.get("."), FileVisitOption.values())
.filter(path -> path.toString().endsWith(".java"))
.forEach(path -> System.out.println(path));
查找的功能其实跟文件的遍历差不多,多了一个匹配器。
System.out.println("\nFiles.find:");
BiPredicate<Path, BasicFileAttributes> matcher = (path, attr) -> path.endsWith(Paths.get("Collec"));
Files
.find(Paths.get("."), 3, matcher, FileVisitOption.values())
.forEach(path -> System.out.println(path.toString()));
由于Iterator/Stream的方法签名不允许抛出IOException,当进行IO操作出现异常时,需要通过不受检查的异常类来传递这个异常信息。UncheckedIOException就是做这个的。
总的来说,io包变化不大,主要是结合Lambda进行一些改进,很多IO方面的改进已经在Java 7里提供了。
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。

sqlldr 可以把文本文件导入到数据库里。
命令行命令:
sqlldr userid=dbUserName/dbName control=sqlldr.ctl log=sqlldr.log bad=sqlldr.bad bindsize=1048576000 rows=500000 readsize=209715200 multithreading=TRUE direct=TRUE;
sqlldr.ctl 是导入的控制文件:
load data
characterset UTF8 # 需要加载中文字符时应在控制文件里指定字符集
infile csv.txt2 # 要导入的数据文件
into table scott.caiyunlog append # 导入的目标表,导入方式是append 追加,还有其他方式见下面
(
ip terminated by '|', # 每个字段可以指定自己的分隔符
rtime terminated by '|',
method terminated by '|',
uri terminated by '|',
proto terminated by '|',
code terminated by '|',
respsize terminated by '|',
T terminated by '|',
D terminated by whitespace # 最后的那个字段没有分隔符,就用空白符,以最后的换行符为分隔符。
)
要注意是errors参数,当错误的数据行数达到这个参数的值时会终止导入。
Usage: SQLLDR keyword=value [,keyword=value,...]
Valid Keywords:
userid -- ORACLE username/password
control -- control file name
log -- log file name
bad -- bad file name
data -- data file name
discard -- discard file name
discardmax -- number of discards to allow (Default all)
skip -- number of logical records to skip (Default 0)
load -- number of logical records to load (Default all)
errors -- number of errors to allow (Default 50)
rows -- number of rows in conventional path bind array or between direct path data saves
(Default: Conventional path 64, Direct path all)
bindsize -- size of conventional path bind array in bytes (Default 256000)
silent -- suppress messages during run (header,feedback,errors,discards,partitions)
direct -- use direct path (Default FALSE)
parfile -- parameter file: name of file that contains parameter specifications
parallel -- do parallel load (Default FALSE)
file -- file to allocate extents from
skip_unusable_indexes -- disallow/allow unusable indexes or index partitions (Default FALSE)
skip_index_maintenance -- do not maintain indexes, mark affected indexes as unusable (Default FALSE)
commit_discontinued -- commit loaded rows when load is discontinued (Default FALSE)
readsize -- size of read buffer (Default 1048576)
external_table -- use external table for load; NOT_USED, GENERATE_ONLY, EXECUTE (Default NOT_USED)
columnarrayrows -- number of rows for direct path column array (Default 5000)
streamsize -- size of direct path stream buffer in bytes (Default 256000)
multithreading -- use multithreading in direct path
resumable -- enable or disable resumable for current session (Default FALSE)
resumable_name -- text string to help identify resumable statement
resumable_timeout -- wait time (in seconds) for RESUMABLE (Default 7200)
date_cache -- size (in entries) of date conversion cache (Default 1000)
no_index_errors -- abort load on any index errors (Default FALSE)
PLEASE NOTE: Command-line parameters may be specified either by
position or by keywords. An example of the former case is 'sqlldr
scott/tiger foo'; an example of the latter is 'sqlldr control=foo
userid=scott/tiger'. One may specify parameters by position before
but not after parameters specified by keywords. For example,
'sqlldr scott/tiger control=foo logfile=log' is allowed, but
'sqlldr scott/tiger control=foo log' is not, even though the
position of the parameter 'log' is correct.
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。
《深入理解Java虚拟机:JVM高级特性与最佳实践》-笔记
根据《Java虚拟机规范》,JVM管理的内存如下:
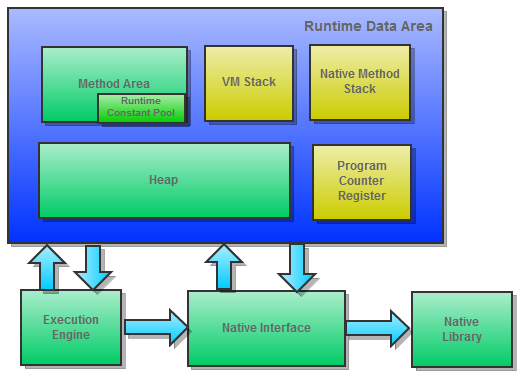
图片来自网络。
其中绿色部分是所有JVM线程共享的,黄色部分是线程独立的。
java.time 包是在JDK8新引入的,提供了用于日期、时间、实例和周期的主要API。
java.time包定义的类表示了日期-时间概念的规则,包括instants, durations, dates, times, time-zones and periods。这些都是基于ISO日历系统,它又是遵循 Gregorian规则的。
所有类都是不可变的、线程安全的。