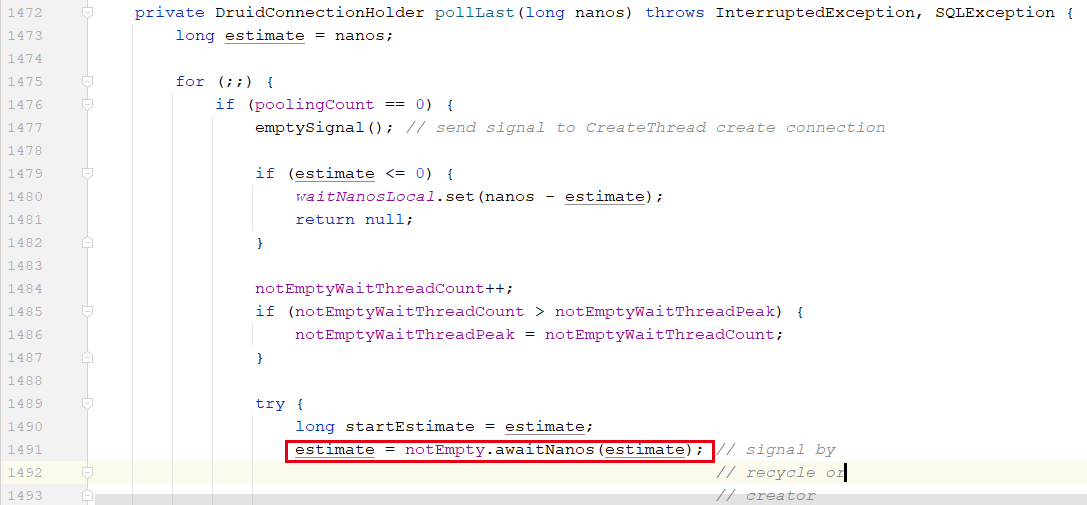
一、问题
测试环境偶尔反馈有个服务 HTTP 请求重复提交。这个 HTTP 请求头里有个 UUID 作为唯一标识,会存入日志表里作为主键的,因为主键冲突,服务端是有打印异常信息的,但客户端完全正常,没有任何错误信息,业务逻辑也正常完成了。
通过查看客户端、服务端两边的日志,怀疑是 HttpURLConnection 自动进行了请求重试。在网上搜索一番,发现已经有人提了 bug JDK-6427251 ,按照这个的操作步骤是可以复现的,包括 JDK 8 的版本。
HttpURLConnection 采用 Sun 私有的一个 HTTP 协议实现类: HttpClient.java
关键是下面这段发送请求、解析响应头的方法:
569 /** Parse the first line of the HTTP request. It usually looks
570 something like: "HTTP/1.0 <number> comment\r\n". */
571
572 public boolean parseHTTP(MessageHeader responses, ProgressSource pi, HttpURLConnection httpuc)
573 throws IOException {
574 /* If "HTTP/*" is found in the beginning, return true. Let
575 * HttpURLConnection parse the mime header itself.
576 *
577 * If this isn't valid HTTP, then we don't try to parse a header
578 * out of the beginning of the response into the responses,
579 * and instead just queue up the output stream to it's very beginning.
580 * This seems most reasonable, and is what the NN browser does.
581 */
582
583 try {
584 serverInput = serverSocket.getInputStream();
585 if (capture != null) {
586 serverInput = new HttpCaptureInputStream(serverInput, capture);
587 }
588 serverInput = new BufferedInputStream(serverInput);
589 return (parseHTTPHeader(responses, pi, httpuc));
590 } catch (SocketTimeoutException stex) {
591 // We don't want to retry the request when the app. sets a timeout
592 // but don't close the server if timeout while waiting for 100-continue
593 if (ignoreContinue) {
594 closeServer();
595 }
596 throw stex;
597 } catch (IOException e) {
598 closeServer();
599 cachedHttpClient = false;
600 if (!failedOnce && requests != null) {
601 failedOnce = true;
602 if (httpuc.getRequestMethod().equals("POST") && (!retryPostProp || streaming)) {
603 // do not retry the request
604 } else {
605 // try once more
606 openServer();
607 if (needsTunneling()) {
608 httpuc.doTunneling();
609 }
610 afterConnect();
611 writeRequests(requests, poster);
612 return parseHTTP(responses, pi, httpuc);
613 }
614 }
615 throw e;
616 }
617
618 }
在第 600 – 614 行的代码里:
- failedOnce 默认是 false,表示是否已经失败过一次了。这也就限制了最多发送 2 次请求。
- httpuc 是请求相关的信息。
- retryPostProp 默认是
true,可以通过命令行参数(-Dsun.net.http.retryPost=false)来指定值。
- streaming:默认
false。 true if we are in streaming mode (fixed length or chunked) 。
通过 Linux 的命令 socat tcp4-listen:8080,fork,reuseaddr system:"sleep 1"\!\!stdout 建立一个只接收请求、不返回响应的 HTTP 服务器。
对于 POST 请求,第一次请求发送出去后解析响应会碰到流提前结束,这是个 SocketException: Unexpected end of file from server,parseHTTP 捕获后发现满足上面的条件就会进行重试。服务端就会收到第二个请求。
继续阅读 →