不同的JVM及其选项会输出不同的日志。
GC 日志
生成下面日志使用的选项:-XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:d:/GClogs/tomcat6-gc.log。
4.231: [GC 4.231: [DefNew: 4928K->512K(4928K), 0.0044047 secs] 6835K->3468K(15872K), 0.0045291 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.445: [Full GC (System) 4.445: [Tenured: 2956K->3043K(10944K), 0.1869806 secs] 4034K->3043K(15872K), [Perm : 3400K->3400K(12288K)], 0.1870847 secs] [Times: user=0.05 sys=0.00, real=0.19 secs]
最前面的数字 4.231 和 4.445 代表虚拟机启动以来的秒数。
[GC 和 [Full GC 是垃圾回收的停顿类型,而不是区分是新生代还是年老代,如果有 Full 说明发生了 Stop-The-World 。如果是调用 System.gc() 触发的,那么将显示的是 [Full GC (System) 。
接下来的 [DefNew, [Tenured, [Perm 表示 GC 发生的区域,区域的名称与使用的 GC 收集器相关。
Serial 收集器中新生代名为 “Default New Generation”,显示的名字为 “[DefNew”。对于ParNew收集器,显示的是 “[ParNew”,表示 “Parallel New Generation”。 对于 Parallel Scavenge 收集器,新生代名为 “PSYoungGen”。年老代和永久代也相同,名称都由收集器决定。
方括号内部显示的 “4928K->512K(4928K)” 表示 “GC 前该区域已使用容量 -> GC 后该区域已使用容量 (该区域内存总容量) ”。
再往后的 “0.0044047 secs” 表示该区域GC所用时间,单位是秒。
再往后的 “6835K->3468K(15872K)” 表示 “GC 前Java堆已使用容量 -> GC后Java堆已使用容量 (Java堆总容量)”。
再往后的 “0.0045291 secs” 是Java堆GC所用的总时间。
最后的 “[Times: user=0.00 sys=0.00, real=0.00 secs]” 分别代表 用户态消耗的CPU时间、内核态消耗的CPU时间 和 操作从开始到结束所经过的墙钟时间。墙钟时间包括各种非运算的等待耗时,如IO等待、线程阻塞。CPU时间不包括等待时间,当系统有多核时,多线程操作会叠加这些CPU时间,所以user或sys时间会超过real时间。
堆的分代
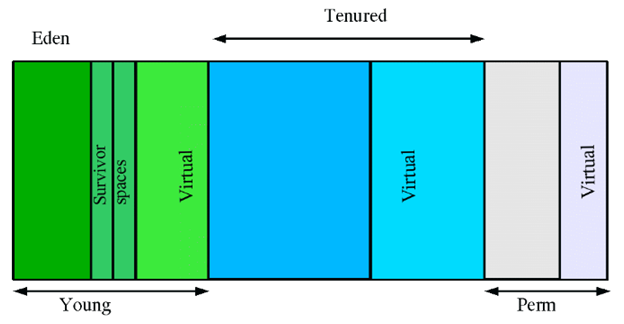
在上图中:
- young区域就是新生代,存放新创建对象;
- tenured是年老代,存放在新生代经历多次垃圾回收后仍存活的对象;
- perm是永生代,存放类定义信息、元数据等信息。
当GC发生在新生代时,称为Minor GC,次收集;当GC发生在年老代时,称为Major GC,主收集。 一般的,Minor GC的发生频率要比Major GC高很多。
JVM GC 相关的选项
-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
-XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
-Xloggc:../logs/gc.log 日志文件的输出路径
欢迎关注我的微信公众号: coderbee笔记,可以更及时回复你的讨论。