本文主要关注与 SpringBoot 集成时的初始化过程。
1. 核心组件
- Configuration:MyBatis所有的配置信息都保存在Configuration对象之中,配置文件中的大部分配置都会存储到该类中。
- SqlSession:MyBatis 的顶层 API,表示与数据库交互的会话,完成数据库增删改查操作。
- Executor:执行器是 MyBatis 调度的核心,负责 SQL 语句的生成和查询缓存的维护。
- StatementHandler:封装了 JDBC Statement 操作,如设置参数等。
- ParameterHandler:负责将用户传递的参数转换成 JDBC Statement 所对应的数据类型。
- ResultSetHandler:负责将 JDBC 返回的 ResultSet 结果集转换成 List 类型的集合。
- TypeHandler:负责将 Java 数据类型和 jdbc 数据类型之间的映射与转换。
- MapperFactoryBean:与 Spring 集成时表示一个 Mapper 原型的工厂 bean,用以创建最终的代理。
- MapperProxy:与一个 mapperInterface 对应,维护了 Map<Method, MapperMethod> 映射。
- MapperAnnotationBuilder:基于注解驱动的 MappedStatement 解析器,解析接口类的每个方法,封装成 MappedStatement。
- MappedStatement:维护了一条 <select|update|delete|insert> 节点的封装。
- SqlSource:负责根据用户传递的 parameterObject 动态生成 SQL 语句,将信息封装成 BoundSql 对象。
- BoundSql:表示动态生成的 SQL 语句以及相应的参数信息。
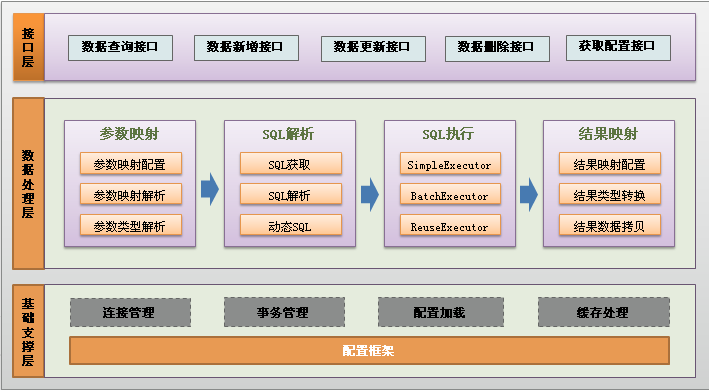
整体架构如下图: