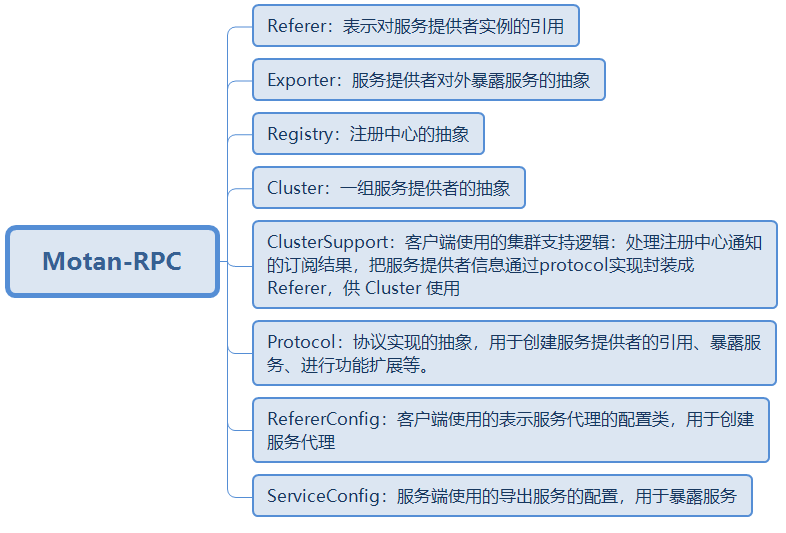
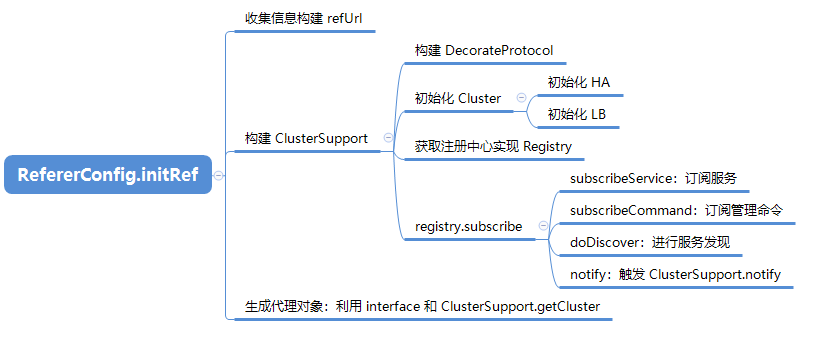
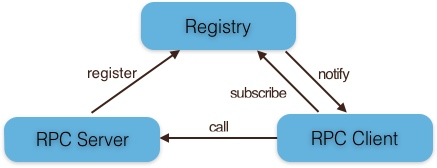
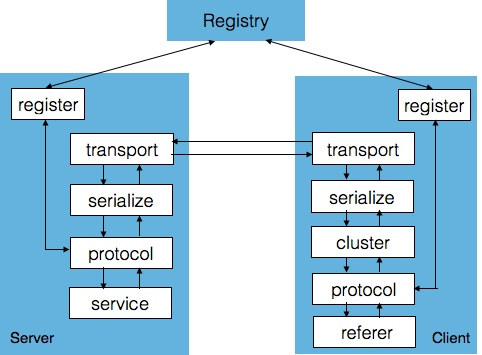
SpringBoot 启动分析 序列文章基于 spring-boot-starter-parent 1.5.19.RELEASE 。
1. 启动一个 SpringBoot 应用
启动一个 SpringBoot 应用只需要下面几行代码即可:
@SpringBootApplication
public class SpringBootDemoApplication {
public static void main(String[] args) {
SpringApplication.run(SpringBootDemoApplication.class, args);
}
}
查看 SpringApplication.run 方法时会来到:
public static ConfigurableApplicationContext run(Object source, String... args) {
return run(new Object[] { source }, args);
}
public static ConfigurableApplicationContext run(Object[] sources, String[] args) {
return new SpringApplication(sources).run(args);
}
可以看到 SpringBoot 的魔法就是那么简单:创建一个 SpringApplication,执行其 run 方法。
就像 “打开冰箱门、把大象塞进冰箱、关上冰箱门” 那么简单、有力。
当然,要了解原理是不能只看高层抽象的。
2. SPI 机制 SpringFactoriesLoader
SpringFactoriesLoader 是 Spring 提供的 SPI 实现机制,从类路径下的 META-INF/spring.factories 文件里加载指定接口的所有实现。以接口的完整类名作为 key,实现类的完整名字作为值,多个实现类用 , 分隔。
下面是 spring-boot-autoconfigure 包下 META-INF/spring.factories 文件里的 一小部分:
# Auto Configure
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.springframework.boot.autoconfigure.admin.SpringApplicationAdminJmxAutoConfiguration,\
org.springframework.boot.autoconfigure.aop.AopAutoConfiguration,\
org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration,\
org.springframework.boot.autoconfigure.batch.BatchAutoConfiguration,\
org.springframework.boot.autoconfigure.cache.CacheAutoConfiguration,\
org.springframework.boot.autoconfigure.cassandra.CassandraAutoConfiguration,\
org.springframework.boot.autoconfigure.cloud.CloudAutoConfiguration,\
SpringFactoriesLoader 内部通过 ClassLoader.getResources 方法来加载类路径下的文件。
继续阅读 →