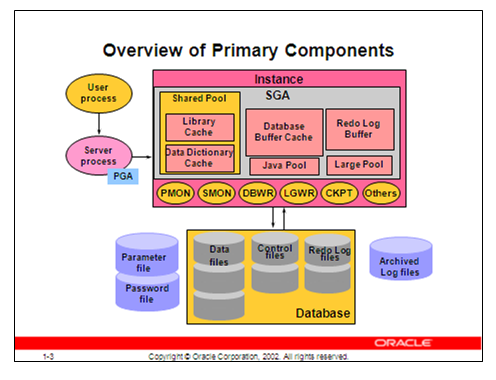
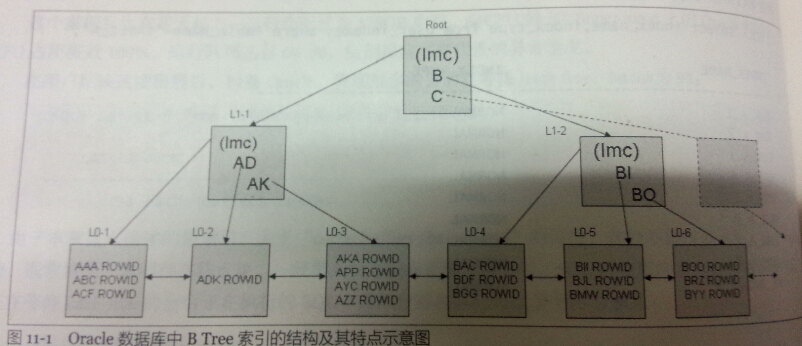
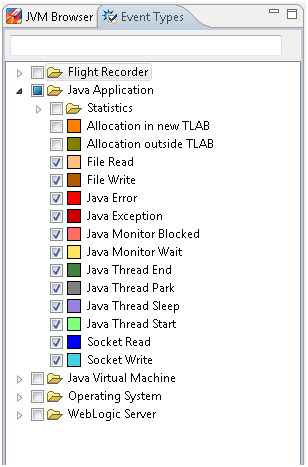
Scala 的预期目标是将面向对象、函数式编程和强大的类型系统结合起来,同时仍然要能写出优雅、简洁的代码。
Scala 视图将以下三组对立的思想融合到一种语言中:
- 函数式编程和面向对象编程
- 富有表达力的语法和静态类型
- 高级的语言特性同事保持与 Java 的高度集成
面向对象编程
面向对象编程是一种自顶向下的程序设计方法,将代码以名词(对象)做切割,每个对象有某种形式的标识符(self/this)、行为(方法)和状态(成员变量)。识别出名词并且定义出它们的行为后,再定义出名词之间的交互。实现交互时,必须将这些交互放在其中一个对象中(而不能独立存在)。现代面向对象设计倾向于定义出”服务类“,将操作多个领域对象的方法集合放在里面。这些服务类虽然也是对象,但通常不具有独立状态,也没有与它们所操作的对象无关的独立行为。
函数式编程
函数式编程方法通过组合和应用函数来构造软件。函数式编程通常倾向于将软件分解为其需要执行的行为或操作,而且通常采用自底向上的方法。函数式编程:对不可变性的强调有助于编写并发程序,视图将副作用推迟到尽可能晚,提供了非常强大的对事物进行抽象和组合的能力。消除副作用使得对程序进行推理(reasoning)变得容易。