系统性能随着并发数量的递增而显著下降的现象,往往是因为没有使用绑定变量而产生大量硬解析所致。
Cursor,游标
Cursor 是 Oracle 数据库里 SQL 解析和执行的载体。有两种类型的 Cursor:Shared Cursor,Session Cursor。
库缓存对象
库缓存(Libaray Cache)实际上是 SGA 中的一块内存(更确切说是 Shared Pool 中的一块内存区域),它的主要作用是缓存刚刚执行过的 SQL 语句和 PL/SQL 语句(如存储过程、函数、包、触发器)所对应的执行计划、解析树(Parse Tree)、Pcode、Mcode 等对象,当同样的 SQL 语句和 PL/SQL 语句再次被执行时,就可以利用缓存在 Libaray Cache 中的那些对象而无须再次从头开始解析,这就提高了这些 SQL 语句和 PL/SQL 语句在重复执行时的执行效率。
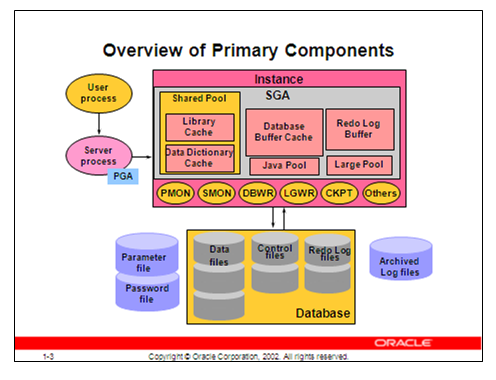
缓存在库缓存中的对象称为库缓存对象(Library Cache Object),所有的库缓存对象都是以一种名为库缓存对象句柄(Library Cache Object Handle)的结构存储在库缓存中的,Oracle 是通过访问相关的库缓存对象句柄来访问对应的库缓存对象的。
库缓存对象句柄是以哈希表(Hash Table)的方式存储在库缓存中的。